Working with WAV Files in Rust
A comparison of Hound and audio_samples for reading and writing WAV.
Disclosure: I am the developer of the crates evaluated in this article: audio_samples, audio_samples_io, wavers, i24, and spectrograms. To support independent verification, the benchmark harness, raw timing data, and analysis scripts are published alongside the article.
audio_samples_io over hound (speedup = hound avg / aus avg), mono, approximately cold cache. Sample types: i16, i32, f32 at 44,100 Hz; 100 Criterion samples per cell. This represents storage-bound single-pass performance, the practical floor for most workloads. Warm-cache and repeated-access results are in the sections below.
TLDR
Use hound when |
Use audio_samples_io when |
|---|---|
| Zero transitive dependencies is a hard requirement (embedded, WASM, audited supply chains) | Performance matters: faster reads in every cache scenario; faster writes at medium-to-large chunk sizes |
Integrating with an existing hound-based codebase |
You want a typed, channel-aware API that encodes format invariants at compile time |
Cold reads (single-pass, approximately storage-bound): audio_samples_io is 1.9–4.5× faster than hound across i16, i32, and f32 on the test machine. DRAM-warm reads: 2.5–8.6×. Streamed reads at 4,096-sample chunks: 10–35× at 60 s. Streamed writes at 4,096-sample chunks, 600 s: 1.78–2.10× across all types, with a small-chunk i16 caveat. The 105× figure is an LLC-warm repeated-access result for 60 s i16 bulk reads; it is not the representative comparison for single-pass workloads, but is representative of workloads where a lot of audio is repeatedly accessed, e.g. machine learning.
WAV files (.wav) are among the most common formats for storing sampled audio data. It most commonly stores uncompressed linear PCM, preserving the source samples exactly at the cost of file size, though the container can also carry compressed codecs.
In Rust, the de facto library for reading and writing .wav files is hound by Ruuda, with over 600 stars on GitHub at the time of writing.
audio_samples is a crate I have developed over the past two years, building on earlier work in the now-archived wavers crate. It provides a unified, channel-aware representation of sampled audio data with a broad range of optional processing capabilities: statistical analysis, resampling, editing, filtering, spectral transforms, parametric EQ, and voice activity detection (VAD), among others. Spectral analysis is implemented via the spectrograms crate, which was spun out of audio_samples to stand on its own; audio_samples integrates it fully through wrapper functions, passing the internal ndarray representation through to the underlying spectrogram routines.
audio_samples itself does not handle file I/O. That responsibility belongs to the companion crate audio_samples_io, which adds .wav and .flac read/write support (FLAC is a story for another day). The separation is intentional: audio_samples operates on audio already in memory, while audio_samples_io manages the disk-facing layer.
This article compares both crates for reading and writing .wav files: their APIs, their design philosophies, and their measured performance. The comparison is most directly applicable to general-purpose Rust audio work on standard targets; where zero-dependency constraints apply, hound's position is largely uncontested and the performance comparison is secondary.
The article is structured in four parts: a side-by-side API walkthrough with working code examples, a benchmark methodology section, results across four conditions (bulk and streamed read/write), and a discussion covering implementation-level causes, practical implications, and broader ecosystem context. The results sections are intentionally detailed, with numbers that require careful qualification by cache scenario and signal duration.[^repo] Readers primarily interested in the practical recommendation can read the API sections and skip directly to the Conclusion.
[^repo]: The benchmark harness, raw timing data, and analysis scripts are published at github.com/jmg049/aus_vs_hound.
What this benchmark does not test. Malformed or non-standard WAV files (e.g. RF64/WAVE64, broadcast WAV metadata, unusual LIST chunks); compressed codecs inside the WAV container; surround formats beyond mono/stereo; network-attached or spinning-disk storage; and independently verified fully-cold cache state (the cold-read setup uses POSIX_FADV_DONTNEED, which is advisory).
A Look at Both Crates
hound
hound models a WAV file as a spec (the header metadata) paired with a typed sample iterator or writer.
You describe the file upfront with a WavSpec, then stream samples in or out one value at a time.
There is no built-in concept of frames or channels; interleaved samples are your responsibility to interpret.
Reading
use hound::WavReader;
fn main() {
let mut reader = WavReader::open("audio.wav").unwrap();
let spec = reader.spec();
println!(
"channels: {}, sample rate: {}, bit depth: {}",
spec.channels, spec.sample_rate, spec.bits_per_sample
);
// Collect every sample into memory at once.
let samples: Vec<i16> = reader
.samples::<i16>()
.map(|s| s.unwrap())
.collect();
println!("read {} samples", samples.len());
}The type parameter on .samples::<T>() must match the file's bit depth and sample format; hound will return an error at runtime otherwise.
All samples land in a flat Vec; interleaving across channels is not unwrapped for you.
.samples() is hound's only read primitive: there is no separate bulk-read or block-read API, so all reads go through the same per-sample iterator regardless of the caller's access pattern.
Writing
use hound::{WavSpec, WavWriter, SampleFormat};
fn main() {
let spec = WavSpec {
channels: 1,
sample_rate: 44_100,
bits_per_sample: 16,
sample_format: SampleFormat::Int,
};
let mut writer = WavWriter::create("output.wav", spec).unwrap();
// Write a 1-second 440 Hz sine wave.
for n in 0..44_100_u32 {
let t = n as f32 / 44_100.0;
let sample = (t * 440.0 * 2.0 * std::f32::consts::PI).sin();
writer.write_sample((sample * i16::MAX as f32) as i16).unwrap();
}
writer.finalize().unwrap();
}The WavSpec must be fully specified before writing starts; there is no way to change it mid-stream.
Calling .finalize() explicitly is strongly recommended: although WavWriter's Drop implementation attempts to finalise the file, any error encountered during drop-time finalisation is silently discarded, so an explicit call is the only way to surface a finalisation failure to the caller.
Streamed Reading
hound does not have a dedicated chunked-read API; the .samples() iterator is the streaming primitive.
You can impose your own chunk window by driving the iterator manually.
The idiomatic first pass is to .collect() each chunk, but that allocates a fresh Vec on every iteration.
To avoid that, pre-allocate with Vec::with_capacity and clear() + push() the buffer each time:
use hound::WavReader;
fn main() {
let mut reader = WavReader::open("audio.wav").unwrap();
let mut iter = reader.samples::<i16>();
let chunk_size = 1024;
let mut buf: Vec<i16> = Vec::with_capacity(chunk_size);
loop {
buf.clear();
for s in iter.by_ref().take(chunk_size) {
buf.push(s.unwrap());
}
if buf.is_empty() {
break;
}
// Process this chunk without holding the full file in memory.
let _ = &buf;
}
}Because .samples() wraps BufReader internally, each call advances the read position; no seeking or manual offset tracking is needed.
The pre-allocated buf is reused across every chunk, so there is no heap allocation in the hot loop.
Streamed Writing
Writing is inherently streamed in hound: write_sample appends one value at a time.
The pattern for chunk-based writing is simply grouping your calls:
use hound::{WavSpec, WavWriter, SampleFormat};
fn main() {
let spec = WavSpec {
channels: 1,
sample_rate: 44_100,
bits_per_sample: 16,
sample_format: SampleFormat::Int,
};
let mut writer = WavWriter::create("output.wav", spec).unwrap();
let chunk_size = 1024;
// Simulate arriving chunks of audio data.
let total_samples = 44_100_u32;
let mut written = 0;
while written < total_samples {
let end = (written + chunk_size as u32).min(total_samples);
for n in written..end {
let t = n as f32 / 44_100.0;
let sample = (t * 440.0 * 2.0 * std::f32::consts::PI).sin();
writer.write_sample((sample * i16::MAX as f32) as i16).unwrap();
}
written = end;
}
writer.finalize().unwrap();
}Each write_sample call goes through hound's internal BufWriter, so the OS-level writes are already batched.
The chunk loop here reflects a realistic producer pattern where audio arrives in blocks rather than all at once.
audio_samples
audio_samples takes a different philosophy: audio is represented as a typed, channel-aware struct (AudioSamples<T>) rather than a flat iterator of interleaved values.
The I/O layer lives in the companion crate audio_samples_io, which exposes both one-shot and streamed read/write paths.
The library owns the concept of frames vs. samples, so you get that structure for free rather than having to reconstruct it yourself.
Reading
use audio_samples_io;
fn main() {
// Reads the file and returns an AudioSamples<i16>.
// Channel count, sample rate, and frame count are embedded in the struct.
let signal = audio_samples_io::read::<_, i16>("audio.wav").unwrap();
println!("{:#}", signal);
}The type parameter selects the in-memory representation you want; if the file's native sample type differs, audio_samples_io handles the conversion automatically.
hound requires the type parameter to match the file's bit depth exactly and will error at runtime if it does not.
The returned AudioSamples<T> knows its own shape (channel count, sample rate, and frame count are all embedded), so there is no flat interleaved Vec to decode manually.
Note: 8-bit WAV samples are stored as unsigned bytes in the WAV spec.
audio_samples_iofollows this convention, so the correct Rust type for 8-bit audio isu8, noti8.
Writing
use audio_samples::{AudioSamples, sample_rate};
use audio_samples_io;
use std::time::Duration;
fn main() {
// Build a 1-second 440 Hz sine wave; channel count and sample rate
// are baked into the AudioSamples struct, so write() needs no spec.
let signal = audio_samples::sine_wave::<i16>(
440.0,
Duration::from_secs(1),
sample_rate!(44100),
1.0,
);
audio_samples_io::write::<_, i16>("output.wav", &signal).unwrap();
}A core design principle of audio_samples is that several degenerate cases are made unrepresentable at the type level. The sample_rate! macro produces a NonZeroU32 at compile time: a zero sample rate is a build error, not a runtime panic. Channel count is enforced by NonZeroU16, making a zero-channel signal impossible to construct. Frame count uses NonZeroUsize, ruling out zero-length audio. The sample data itself is stored as a NonEmptyVec, preventing construction of a signal with an allocated but empty buffer. These constraints are not just documentation conventions; they are part of the type signatures. Code that compiles is guaranteed to carry a non-zero sample rate, at least one channel, at least one frame, and at least one sample.
Because all the metadata travels with the AudioSamples value, there is no separate spec struct to fill out; the writer derives everything it needs from the signal itself.
For the one-shot write() path, there is no manual finalize() step: the write is completed before write() returns. The streamed write path does retain an explicit finalize() call so that errors during chunk flushing can be surfaced to the caller.
Streamed Reading
audio_samples_io has a dedicated streaming API.
You open a StreamedReader, read metadata from it directly, allocate a buffer sized to match, then pull frames in a loop, all from the same open handle:
use audio_samples::{AudioSamples, nzu};
use audio_samples_io::open_streamed;
fn main() {
let chunk_size nzu!(1024);
// Open once: channel count and sample rate are available on the live reader.
let mut streamed = open_streamed("audio.wav").unwrap();
let sr = streamed.sample_rate;
// Allocate once; read_frames_into reuses this allocation every iteration.
let mut buffer = AudioSamples::<i16>::zeros_mono(chunk_size, sr);
while streamed.remaining_frames() > 0 {
streamed.read_frames_into(&mut buffer, chunk_size).unwrap();
// Process this chunk without holding the full file in memory.
let _ = &buffer;
}
}The notable design difference from hound here is that read_frames_into requires you to hand it a buffer; the API makes reuse the only option.
With hound the natural idiom is .collect(), which allocates a fresh Vec each iteration; you can avoid that by using Vec::with_capacity(chunk_size) and clear() + extend() in the loop, but the API does not push you there.
The remaining_frames() counter also gives an explicit termination condition rather than relying on an empty read.
The trade-off is some call-site ceremony: constructing the buffer requires explicit NonZeroUsize and NonZeroU32 values, obtained via .unwrap() in the example above; hound's equivalent parameters are plain integers.
For multi-channel files, replace zeros_mono with zeros_multi:
use std::num::NonZeroU32;
let nz_ch = NonZeroU32::new(channels as u32).unwrap();
let mut buffer = AudioSamples::<i16>::zeros_multi(nz_ch, chunk_size, sr);Streamed Writing
The streamed write path mirrors the read path.
You create a StreamedWriter with create_streamed, push AudioSamples chunks through write_frames, then call finalize:
use audio_samples::{AudioSamples, sample_rate};
use audio_samples_io::{create_streamed, traits::AudioStreamWrite};
use std::time::Duration;
fn main() {
let sr = sample_rate!(44100);
let total_frames: usize = 44_100; // 1 second
// Pre-build one chunk of audio to push repeatedly.
let chunk_dur = Duration::from_secs_f64(1024.0 / 44_100.0);
let chunk = audio_samples::sine_wave::<i16>(440.0, chunk_dur, sr, 1.0);
let chunk_frames = chunk.len().get();
// The type parameter T fixes the on-disk sample format at creation time.
let mut writer = create_streamed::<_, i16>("output.wav", 1, 44_100).unwrap();
let mut written = 0;
while written < total_frames {
writer.write_frames(&chunk).unwrap();
written += chunk_frames;
}
writer.finalize().unwrap();
}The type parameter T on create_streamed fixes the on-disk sample format at the call site, playing the same role as WavSpec in hound but encoded in the type rather than a separate struct.
Unlike hound's write_sample, write_frames accepts a whole AudioSamples chunk at once, so the chunking granularity is explicit in the call rather than implied by how many times you call the API.
Methodology
All benchmarks were run on a single machine in release mode with link-time optimisation enabled (lto = true, codegen-units = 1, opt-level = 3).
The timing harness uses the criterion benchmarking framework (benches/wav_benches.rs).
Criterion determines iteration counts adaptively based on measurement time budgets, performs automatic outlier detection, and reports confidence intervals.
The control flow and usage code for both libraries are identical within the benchmark functions; both use the same b.iter_custom timing wrapper, which times each individual iteration and accumulates elapsed time before returning the total to Criterion.
The benchmark harness (benches/wav_benches.rs), raw per-iteration results (CSV format), and analysis and plotting scripts (analyse.py) are all available in the same repository as this article. All reported figures can be reproduced by running cargo bench followed by python analyse.py --csv criterion_out.csv --out criterion_out/.
Crate versions
| Crate | Version |
|---|---|
hound |
3.5.1 |
audio_samples |
1.0.11 (bare-bones feature) |
audio_samples_io |
0.3.2 (wav feature) |
Test environment
| Property | Value |
|---|---|
| CPU | AMD EPYC-Genoa (virtual) |
| vCPUs | 2 (1 thread per core, SMT disabled) |
| L2 cache | 2 × 1 MiB |
| L3 cache | 32 MiB (shared) |
| RAM | ≈ 3.8 GiB |
| Storage | QEMU virtual disk (/dev/sda, ROTA=0, mq-deadline scheduler) |
| OS | Ubuntu 26.04 LTS (Resolute Raccoon) |
| Kernel | 7.0.0-15-generic |
| CPU frequency governor | N/A (no cpufreq scaling reported) |
| SMT | disabled |
| CPU affinity | none (affinity list: CPUs 0,1) |
| ASLR | enabled (level 2, full) |
| Filesystem | ext4 (rw,relatime, no compression, no CoW) |
Several settings are worth noting as potential confounds.
The machine is a virtual machine (QEMU/KVM), so CPU clock characteristics and storage latency are subject to hypervisor scheduling.
No CPU-affinity pinning was applied; the OS scheduler was free to migrate the benchmark process between the two vCPUs.
The ext4 filesystem has no compression or copy-on-write overhead, so write benchmarks measure library serialisation and raw I/O time without the additional zstd cost present on btrfs+compress setups.
The 32 MiB L3 cache is the key architectural feature driving the speedup discontinuity in the results: files up to ≈ 30 MiB fit in the LLC across thousands of iterations, yielding LLC-bandwidth-limited reads for audio_samples_io; larger files spill to DRAM.
Signal
Each benchmark operates on a 440 Hz sine wave sampled at 44,100 Hz. The signal is pre-generated once, before the timed loop begins, so what is measured is the I/O operation alone and not sample generation. Write benchmarks measure creating a file, flushing all data, and finalising the header; read benchmarks measure opening a file and reading all of its data into memory.
Signal durations of 1, 5, 10, 30, 60, 300, and 600 seconds were tested, giving file sizes from ~88 KB (1 s, i16, mono) to ~212 MB (600 s, i32/f32, stereo).
Three sample types were benchmarked: i16, i32, and f32. Although audio_samples and audio_samples_io also support i24 (24-bit integers), hound v3.5.1 does not implement the i24 sample type; a cross-library comparison for that dtype is therefore not possible and i24 is absent from the sweep.
Both mono (1-channel) and stereo (2-channel) signals were benchmarked to verify behaviour under interleaved multi-channel data.
Benchmark conditions
Four conditions were measured for each library, dtype, and duration:
- Bulk read: open the file and read all samples into a single in-memory allocation in one call.
- Bulk write: create the file, write all pre-generated samples, and finalise.
- Streamed read: open the file and pull samples into a fixed-size buffer chunk by chunk.
Both libraries use an allocation-free pattern here:
houndusesVec::with_capacity(chunk_size)withclear()+push()on each iteration;audio_samples_iousesread_frames_intowith a pre-allocatedAudioSamples<T>buffer. Neither library allocates inside the hot loop. - Streamed write: create the file, push a pre-generated chunk repeatedly until the full signal duration has been written, and finalise.
For the streaming conditions, chunk sizes of 512, 1024, 4096, 8192, and 16384 samples were swept.
Measurement
Criterion determines iteration counts adaptively from measurement time budgets (default: 3 s warmup, 5 s measurement per benchmark). 100 samples were collected per benchmark configuration; each sample consists of one or more timed iterations, with the per-sample iteration count chosen by Criterion based on the per-iteration duration. Criterion's warmup phase brings file-system caches to a steady state and allows the allocator to settle before measurement begins. Each iteration opens or creates the file from scratch; no file handle is reused across iterations.
std::hint::black_box is applied to the result of every read to prevent the compiler from eliminating the work as dead code.
The reported statistics are:
| Statistic | Meaning |
|---|---|
| avg | arithmetic mean across all 100 collected Criterion samples |
| cv | coefficient of variation (σ / mean); values above 0.5 indicate high variance |
All times are in milliseconds. Where cv is high, OS scheduling or filesystem jitter is likely a contributing factor.
Benchmark Results
Bulk Read
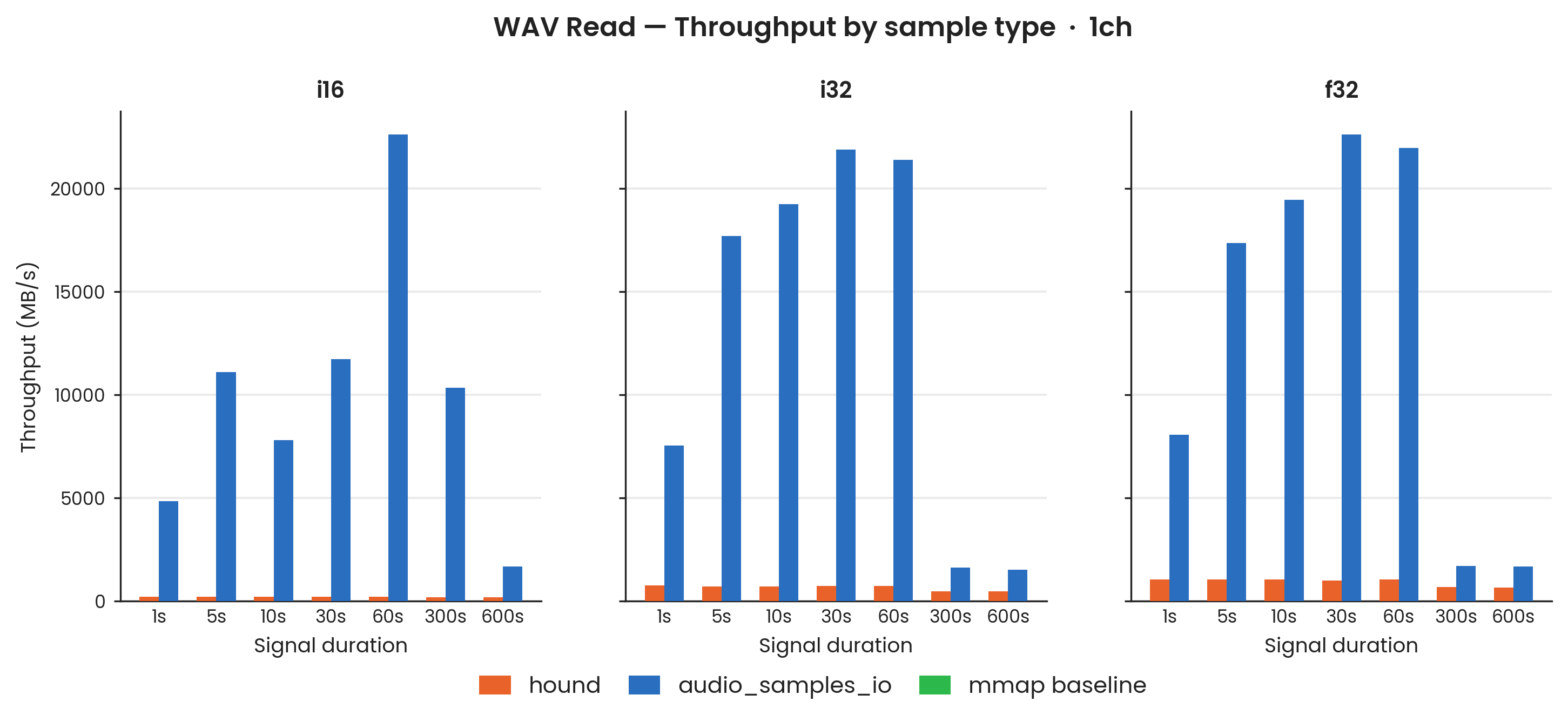
i16, i32, f32 at 44,100 Hz; mono (1-channel). 100 Criterion samples; Criterion warmup phase excluded. Cache condition: warm — files are page-cache resident after warmup completes.
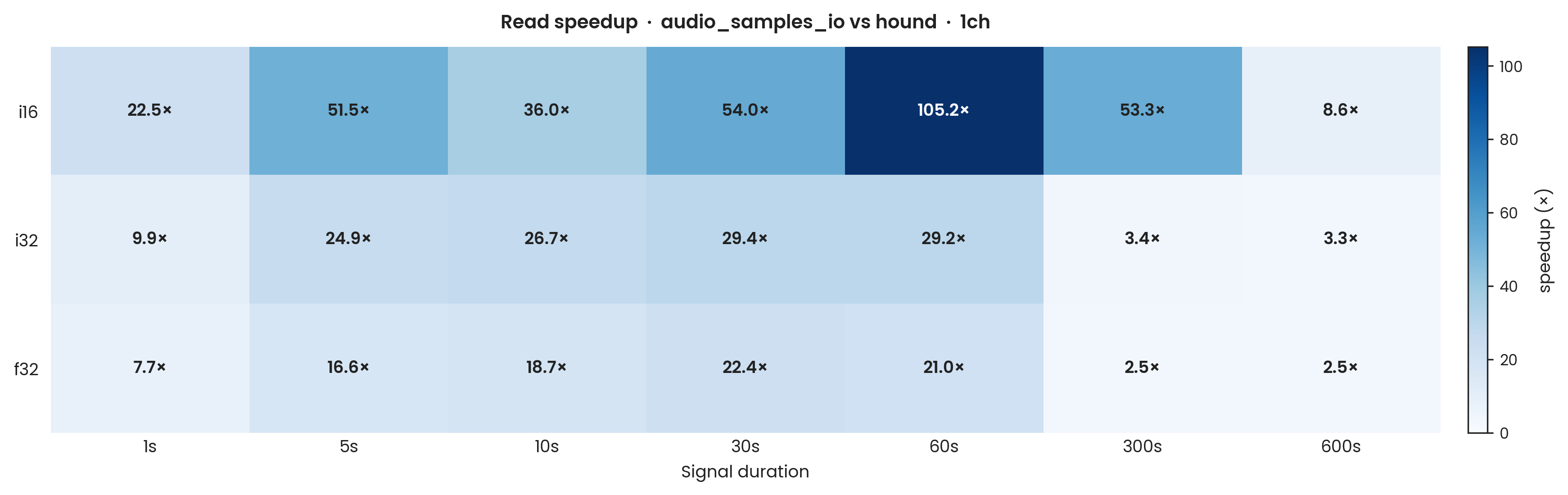
hound, mono (warm cache). Y-axis: speedup ratio (hound avg ÷ aus avg); values above 1 indicate audio_samples_io is faster. X-axis: signal duration (seconds, log scale). Sample types: i16, i32, f32; mono (1-channel). Same Criterion sample count as Figure 1. Error bars: propagated ±1σ uncertainty, σR = R√((σH/H)² + (σA/A)²); full per-condition values are in the published CSV.
audio_samples_io is substantially faster than hound for bulk reads across every dtype and duration tested.
The speedup is highest at intermediate durations and shows a pronounced discontinuity around the processor's last-level cache (LLC) capacity.
For i16, the speedup peaks at approximately 105× at 60 s, where the 5.3 MB file is firmly LLC-resident.
The 300 s file (≈ 26 MB) also fits within the 32 MiB LLC and maintains a 53× speedup; the 600 s file (≈ 53 MB) spills to DRAM and the speedup falls to 8.6×.
For i32 and f32 (four bytes per sample), the LLC boundary falls between 60 s and 300 s: the speedup is approximately 29× for i32 and 21× for f32 at 60 s (LLC-resident), dropping to 3.3–3.4× for i32 and 2.5× for f32 at 300–600 s once files exceed the LLC.
In absolute terms, hound reads a 600 s i16 mono file (≈ 53 MB) in 271.5 ms on average; audio_samples_io reads the same file in 31.7 ms.
The spread across samples is also much tighter for audio_samples_io: its standard deviation is consistently smaller than hound's at short and medium durations.
The table below shows the audio_samples_io speedup over hound across all tested durations for mono signals. The figures above show the underlying throughput curves.
Bulk read speedup (hound avg / aus avg), mono, warm cache
| Duration | i16 speedup |
i32 speedup |
f32 speedup |
|---|---|---|---|
| 1 s | 22× | 10× | 8× |
| 5 s | 51× | 25× | 17× |
| 10 s | 36× | 27× | 19× |
| 30 s | 54× | 29× | 22× |
| 60 s | 105× | 29× | 21× |
| 300 s | 53× | 3.4× | 2.5× |
| 600 s | 8.6× | 3.3× | 2.5× |
Speedup =
houndavg /ausavg (values > 1 meanaudio_samples_iois faster). Propagated 1σ uncertainty (σ_R = R√((σ_H/H)² + (σ_A/A)²)) is included in the full per-condition data in the published CSV.
600 s · mono · warm-cache bulk read (100 Criterion samples)
| Benchmark | avg (ms) | cv |
|---|---|---|
hound · i16 |
271.507 | 0.016 |
aus · i16 |
31.717 | 0.036 |
hound · i32 |
227.914 | 0.036 |
aus · i32 |
69.372 | 0.054 |
hound · f32 |
159.134 | 0.037 |
aus · f32 |
63.233 | 0.024 |
The step-change in speedup reflects the LLC capacity of this machine.
For i16 mono, the file at 60 s is ≈ 5.3 MB and fits well within the LLC, giving audio_samples_io a 105× advantage reading at L3 bandwidth.
The 300 s file (≈ 26 MB) also fits within the 32 MiB LLC, but its larger footprint increases cache pressure, and the speedup settles at 53×; at 600 s the 53 MB file spills to DRAM and the speedup falls to 8.6×.
For i32 and f32 the LLC boundary falls between 60 s and 300 s: the 60 s file (≈ 10.6 MB) is LLC-resident (29× for i32, 21× for f32), while the 300 s file (≈ 53 MB) exceeds the LLC so the speedup drops to 3.3–3.4× for i32 and 2.5× for f32.
Stereo (2-channel) Bulk Read
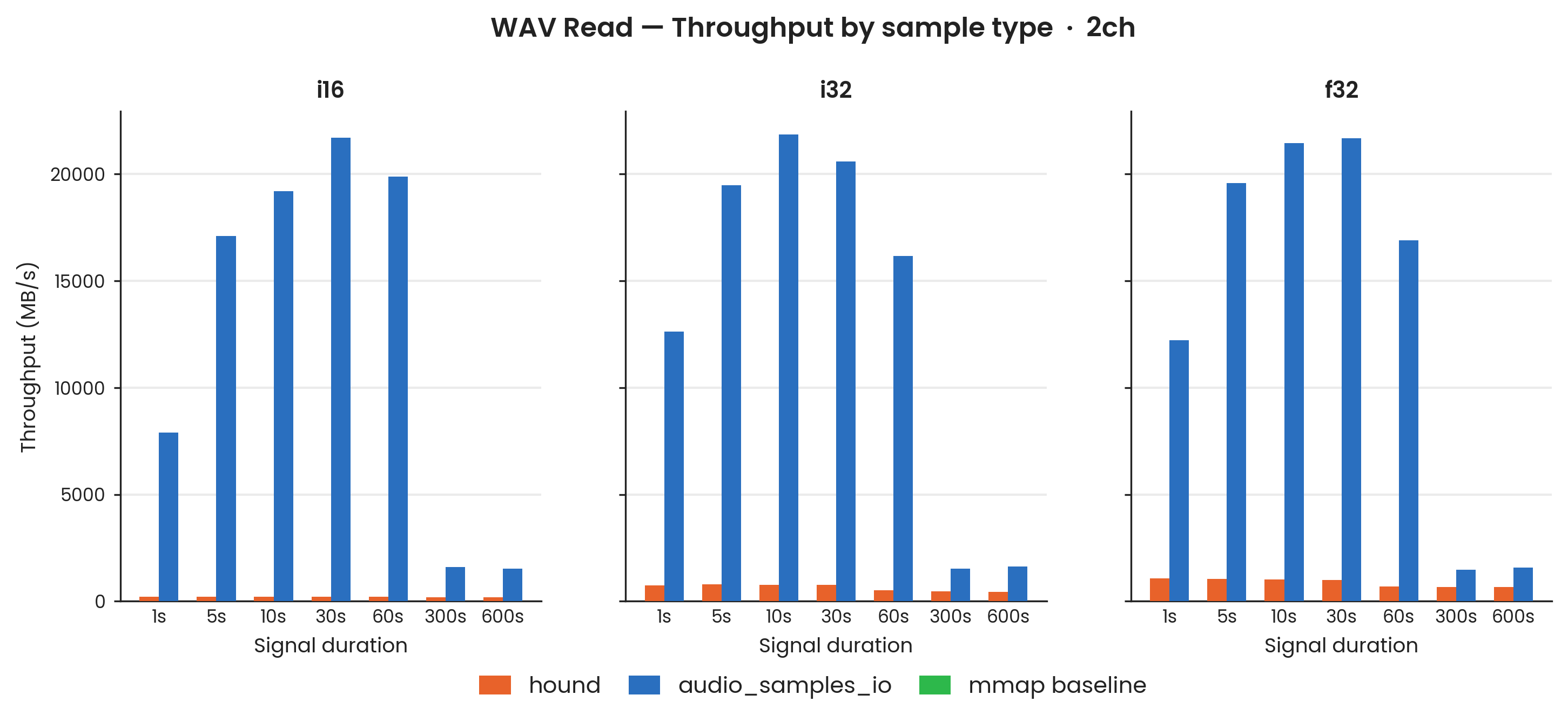
i16, i32, f32 at 44,100 Hz; stereo (2-channel, interleaved). Shaded bands: ±1σ. Stereo results closely mirror mono; deinterleaving overhead is negligible at these file sizes.
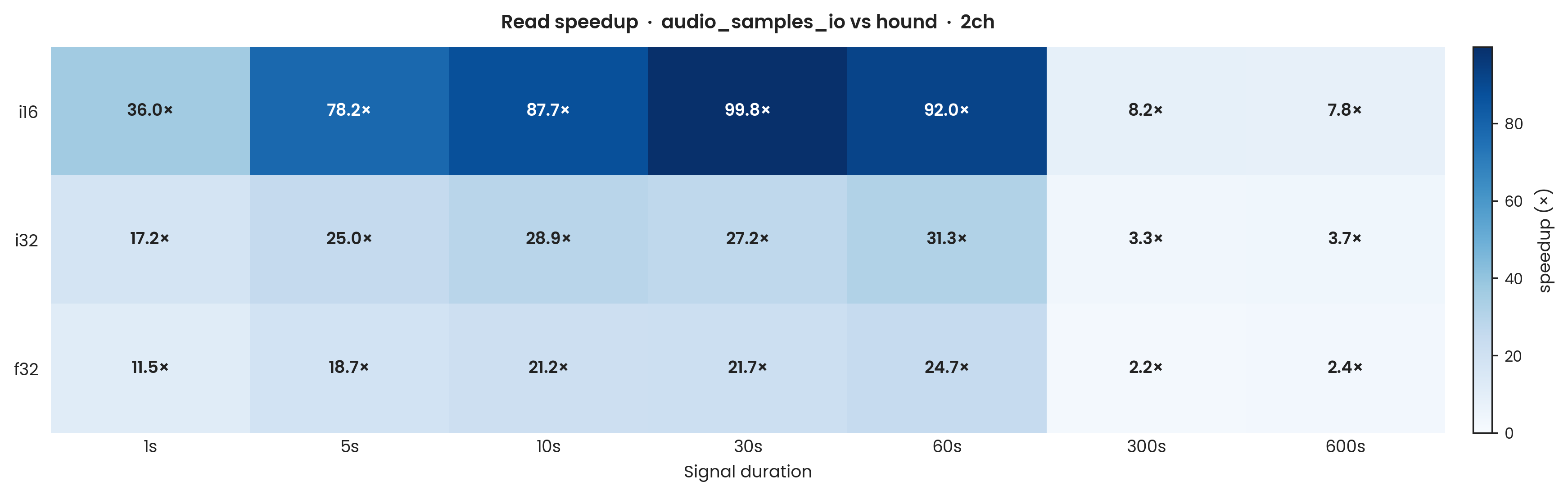
hound, stereo (warm cache). Same axes and Criterion methodology as Figure 2. Sample types: i16, i32, f32; stereo (2-channel). Error bars: propagated ±1σ. Speedup profiles closely mirror mono (Figure 2), confirming that channel count does not affect the relative advantage at these signal lengths.
Stereo results closely mirror mono across every dtype and duration.
The speedup ranges for stereo i16 are similar to mono (≈ 8× at 600 s; ≈ 78× at 5 s), and i32/f32 stereo speedups are within a few multiples of their mono counterparts.
The deinterleaving step required for multi-channel reads adds negligible overhead at 44,100 Hz stereo relative to the bulk read gain, so channel count neither boosts nor penalises the result at these signal lengths.
Bulk Write
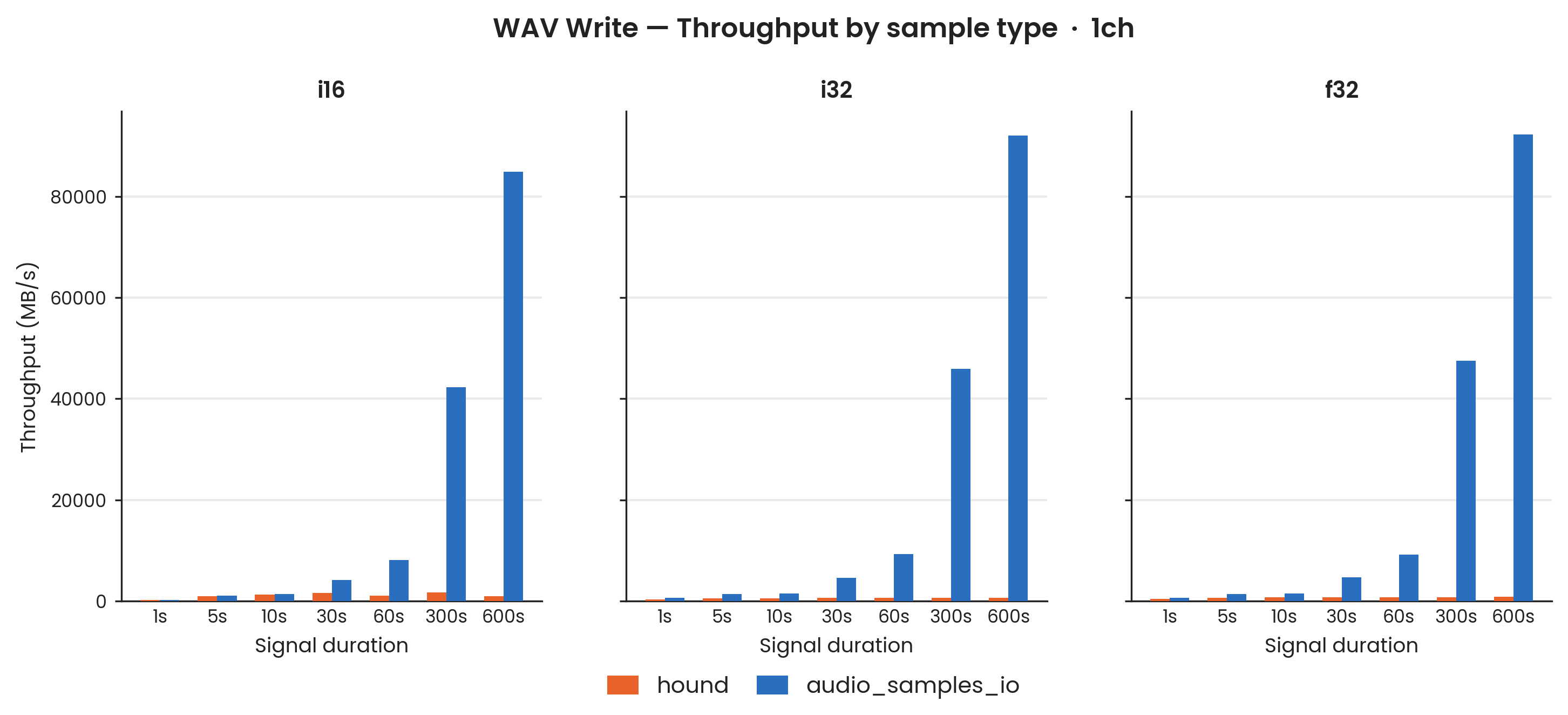
i16, i32, f32 at 44,100 Hz; mono (1-channel). 100 Criterion samples; Criterion warmup excluded. Shaded bands: ±1σ. Write benchmarks run on ext4 (no compression); absolute MB/s figures reflect library serialisation and raw I/O time.
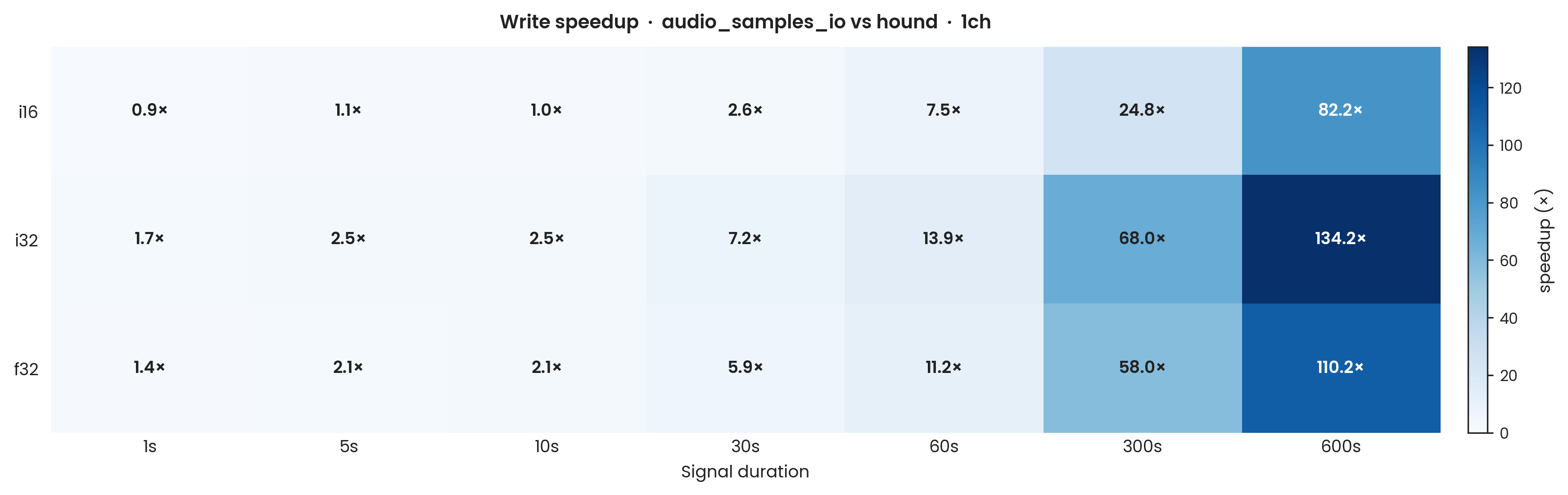
hound, mono. Y-axis: speedup ratio (hound avg ÷ aus avg); values above 1 indicate audio_samples_io is faster. X-axis: signal duration (seconds, log scale). Sample types: i16, i32, f32; mono (1-channel). Error bars: propagated ±1σ. The i16 series uses hound's optimised SampleWriter16 path (the fastest available write API for that dtype) for both bulk and streamed writes.
audio_samples_io is consistently faster across all dtypes.
At short durations the margins are modest: for i16 the advantage at 10 s is negligible (≈ 1.05×), while for i32 and f32 it is more meaningful at approximately 2.5× and 2.1× respectively.
At longer durations the advantage grows substantially, reaching 82× for i16, 134× for i32, and 110× for f32 at 600 s.
10 s · mono · write (100 Criterion samples)
| Benchmark | avg (ms) | cv |
|---|---|---|
hound · i16 |
0.672 | 0.051 |
aus · i16 |
0.640 | 0.048 |
hound · i32 |
2.883 | 0.047 |
aus · i32 |
1.149 | 0.071 |
hound · f32 |
2.399 | 0.026 |
aus · f32 |
1.137 | 0.066 |
Write CV values at 10 s are in the 3–7% range for both libraries.
Streamed Read
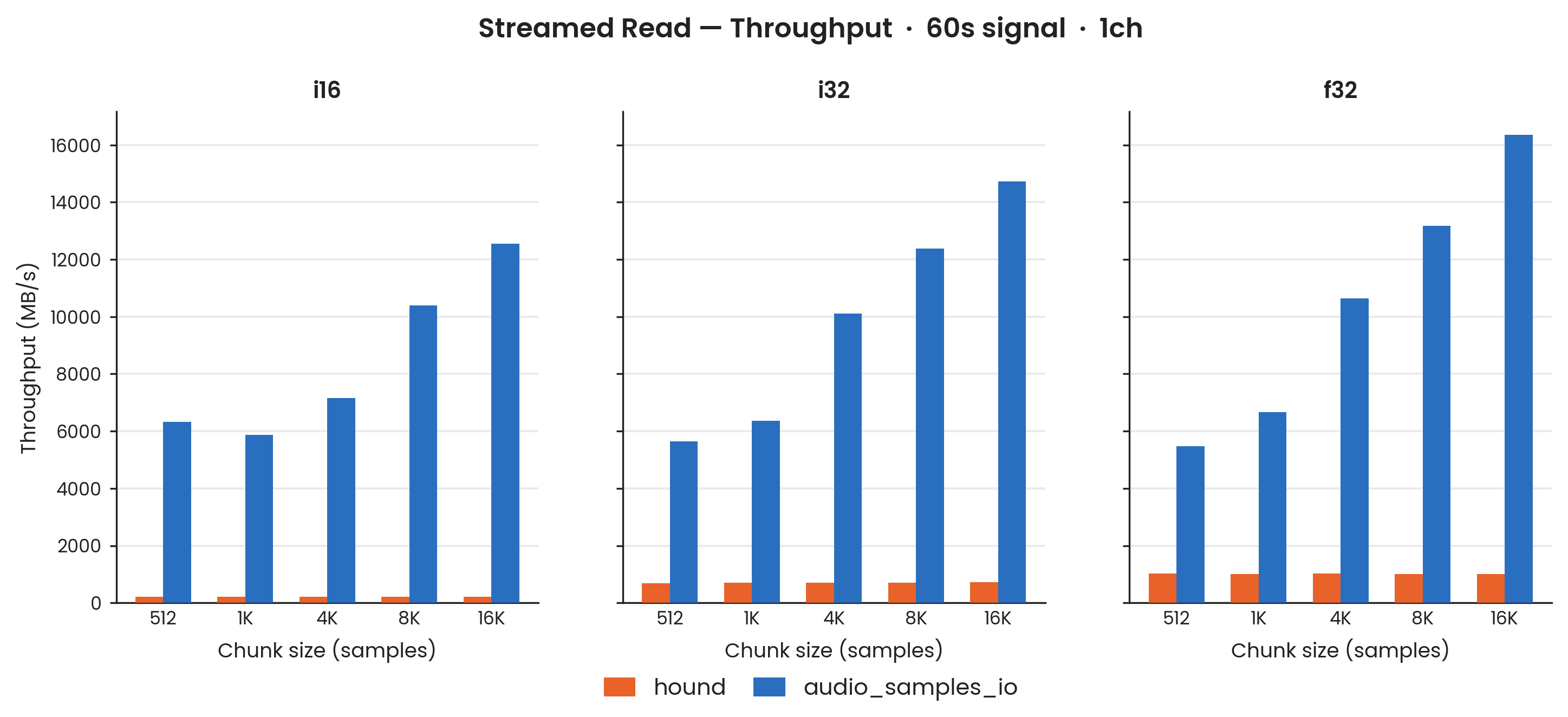
i16, i32, f32. 100 Criterion samples; Criterion warmup excluded. Shaded bands: ±1σ. Cache condition: warm. Both libraries use allocation-free chunk patterns; neither allocates inside the hot loop.
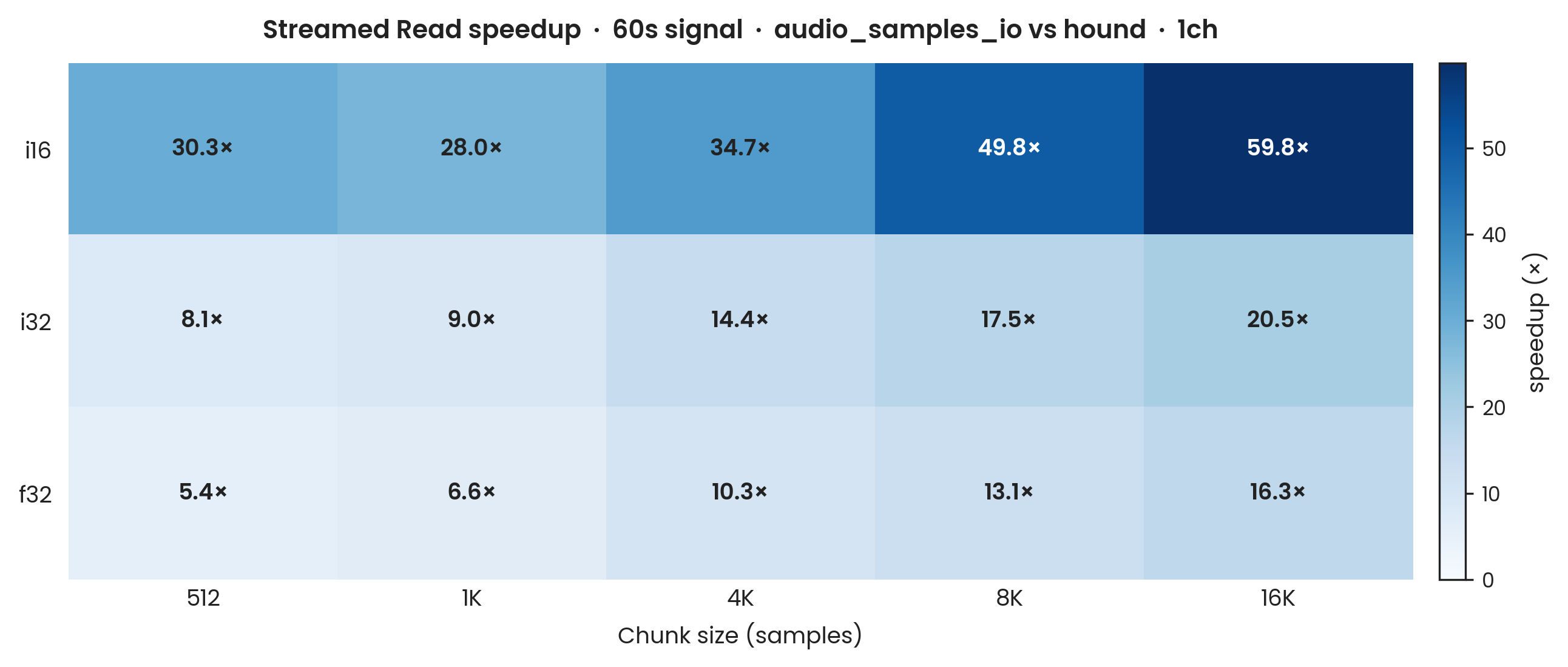
hound, 60 s, mono (warm cache). Y-axis: speedup ratio (hound avg ÷ aus avg); values above 1 indicate audio_samples_io is faster. X-axis: chunk size in samples (512–16,384). Fixed duration: 60 s; mono (1-channel). Sample types: i16, i32, f32. 100 Criterion samples. Error bars: propagated ±1σ. hound's streamed-read time is flat across chunk sizes because its iterator advances one sample at a time regardless of how the caller groups reads.
The read advantage for audio_samples_io carries over to the streamed path and is stable across all chunk sizes.
At 60 s with a 4,096-sample chunk: 35× for i16, 14× for i32, 10× for f32.
At 600 s (table below) the speedups are lower due to the LLC spill effect described above.
Within each duration, larger chunk sizes (8 K–16 K) tend to favour audio_samples_io slightly more than smaller ones.
hound's streamed-read time is essentially flat across chunk sizes at a given duration, as expected: the iterator advances one sample at a time regardless of how the caller groups the results.
Standard deviation for audio_samples_io remains tight across the board; hound's deviation is proportionally lower here than in bulk mode, but its absolute times are still much higher.
The table below shows absolute timings at 600 s with a 4,096-sample chunk.
600 s · mono · streamed read · chunk 4,096 (100 Criterion samples)
| Benchmark | avg (ms) | cv |
|---|---|---|
hound · i16 |
252.510 | 0.018 |
aus · i16 |
9.117 | 0.020 |
hound · i32 |
148.928 | 0.045 |
aus · i32 |
14.084 | 0.025 |
hound · f32 |
105.098 | 0.038 |
aus · f32 |
13.356 | 0.023 |
Speedups here are 28× for i16, 11× for i32, and 7.9× for f32.
hound · i32 reads measurably slower than hound · f32 despite identical on-disk byte counts.
The cause is in hound's Sample::read() dispatch: the i32 implementation matches against six arms ((1,8), (2,16), (3,24), (4,24), (4,32), and a wildcard) before reaching the 32-bit integer case, while the f32 implementation reaches its only relevant arm (4,32) immediately.
Over 26.5 million samples in a 600 s file, this extra per-sample branch evaluation is consistent with the ≈ 44 ms gap between hound · i32 (148.9 ms) and hound · f32 (105.1 ms) in the streamed read results; profiling with perf would be needed to confirm the exact source of the difference.
Streamed Write
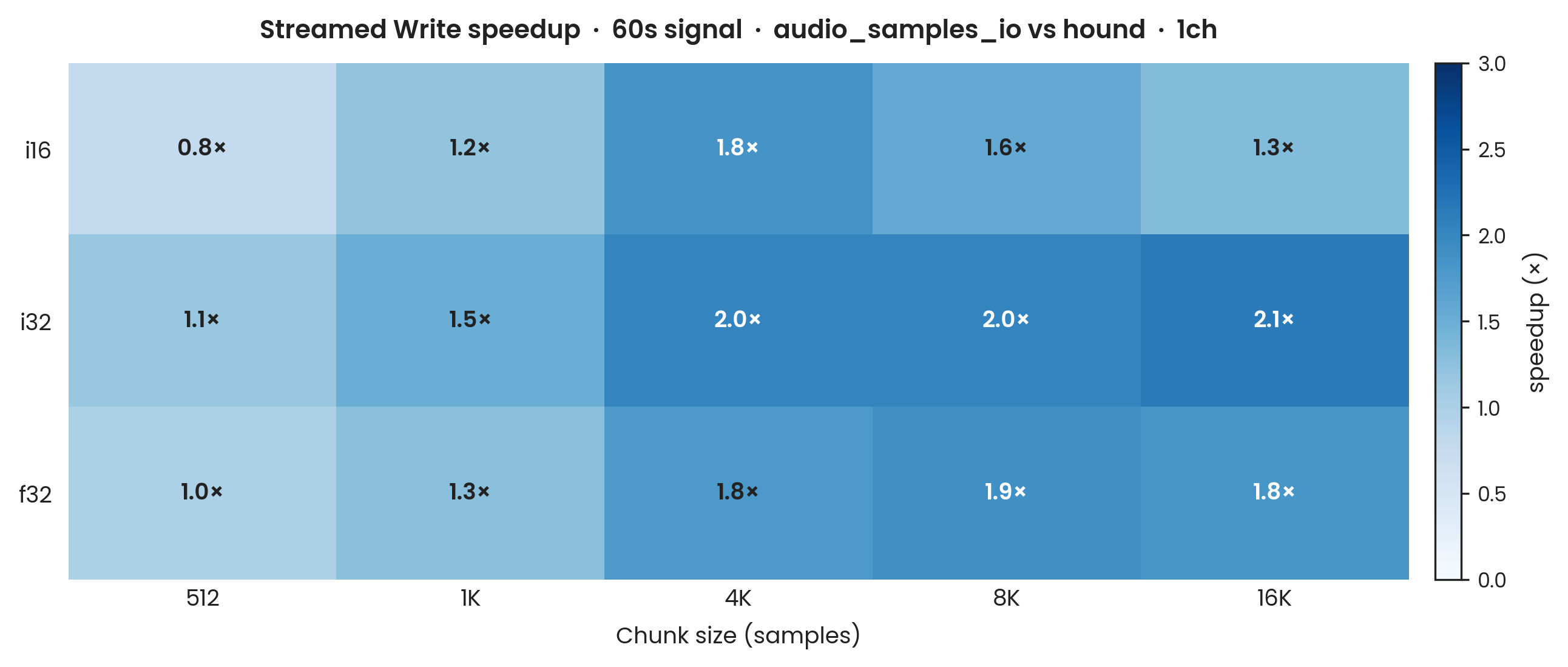
hound, 60 s, mono. Y-axis: speedup ratio (hound avg ÷ aus avg); values above 1 indicate audio_samples_io is faster; linear scale. X-axis: chunk size in samples (512, 1,024, 4,096, 8,192, 16,384). Fixed duration: 60 s at 44,100 Hz; mono (1-channel). Sample types: i16, i32, f32. 100 Criterion samples; Criterion warmup excluded. Error bars: propagated ±1σ. Write benchmarks run on ext4 (no compression). The i16 series uses hound's get_i16_writer path (the optimised SampleWriter16 bulk-flush API) for every chunk.
Streamed write shows a clear chunk-size dependence for i32 and f32, and a more complex pattern for i16.
At small chunk sizes (512 samples), audio_samples_io is slower than hound for i16 (≈ 0.77× at 60 s), roughly equal for f32, and only modestly faster for i32 (≈ 1.15×).
The advantage emerges clearly at larger chunks: at 4,096 samples audio_samples_io is approximately 1.83× faster for i16, 2.03× for i32, and 1.77× for f32.
For short durations (1 s, 5 s), results are noisier in general due to OS scheduling and file-open overhead, but the qualitative ordering is unchanged at medium and large chunk sizes.
The table below shows the raw timing at 600 s with a 4,096-sample chunk.
600 s · mono · streamed write · chunk 4,096 (100 Criterion samples)
| Benchmark | avg (ms) | cv |
|---|---|---|
hound · i16 |
72.411 | 0.143 |
aus · i16 |
39.315 | 0.040 |
hound · i32 |
147.681 | 0.042 |
aus · i32 |
70.441 | 0.048 |
hound · f32 |
128.090 | 0.090 |
aus · f32 |
72.157 | 0.056 |
Speedups at this chunk size are 1.84× (i16), 2.10× (i32), and 1.78× (f32).
CV values are 4–14%.
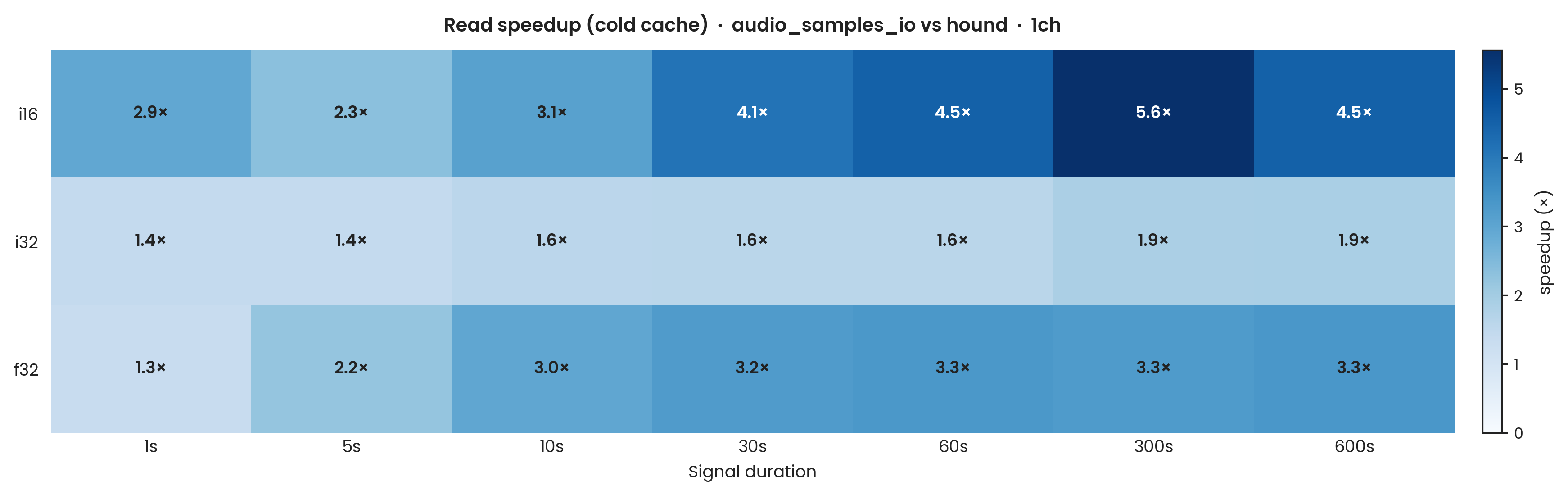
Cold-cache Bulk Read
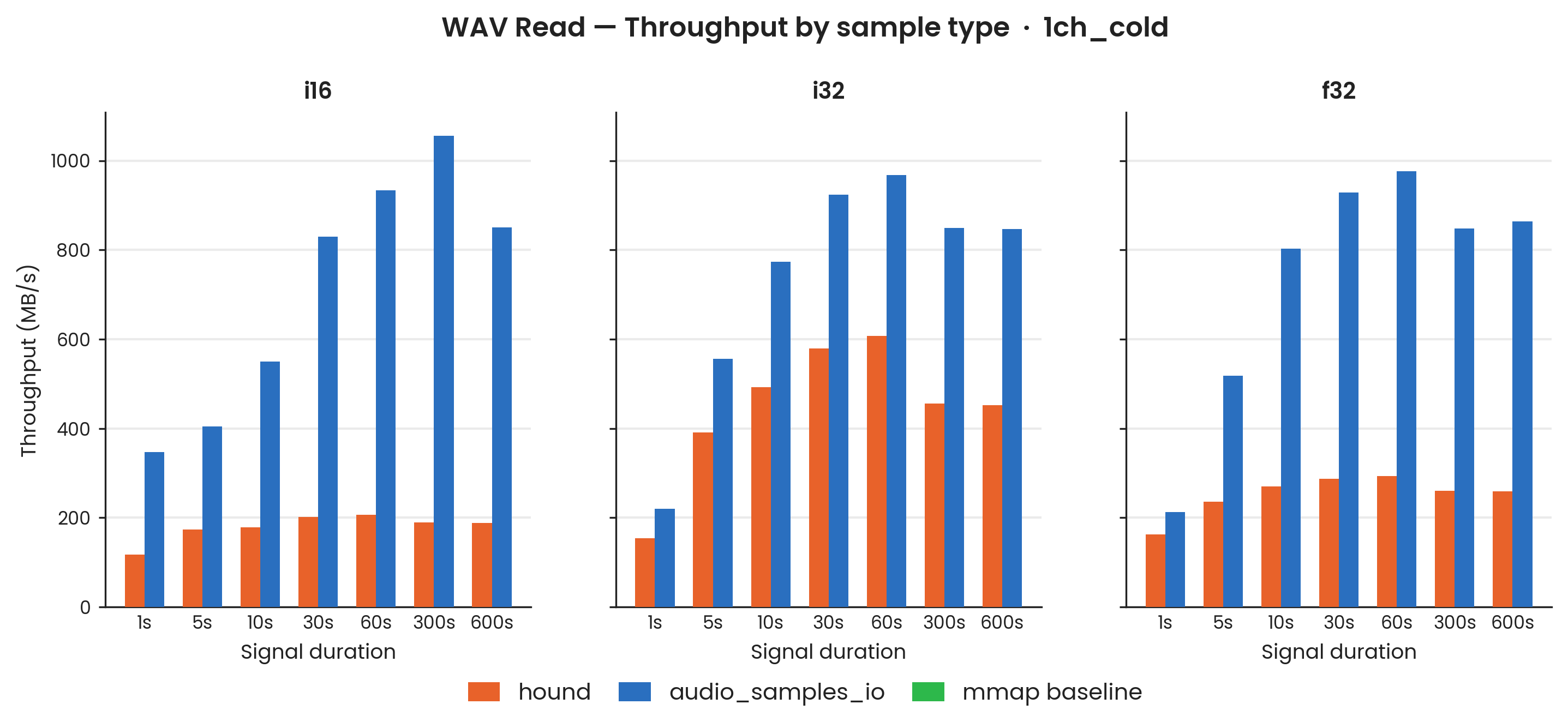
hound, audio_samples_io. Sample types: i16, i32, f32; mono (1-channel). 100 Criterion samples. Cache eviction: POSIX_FADV_DONTNEED called before each iteration (advisory; eviction not independently verified). Results should be treated as approximately storage-bound rather than guaranteed cold. Error bars: ±1σ.
To characterise storage-bound performance, bulk read benchmarks were repeated with posix_fadvise(POSIX_FADV_DONTNEED) called before each measured iteration to advise the kernel to evict the file from the page cache.
POSIX_FADV_DONTNEED is advisory: the kernel may ignore it, and eviction was not independently verified (e.g. via vmtouch); results should be treated as approximately storage-bound rather than guaranteed cold. POSIX_FADV_DONTNEED is issued inside iter_custom before each individual timed iteration.
The storage device here appears to be significantly faster than typical SATA storage, and hound's per-sample CPU overhead is still clearly visible as a bottleneck even under cold-read conditions.
600 s · mono · cold-cache read (100 Criterion samples)
| Benchmark | avg (ms) | cv |
|---|---|---|
hound · i16 |
280.171 | 0.016 |
aus · i16 |
62.241 | 0.058 |
hound · i32 |
234.104 | 0.033 |
aus · i32 |
124.946 | 0.039 |
hound · f32 |
407.846 | 0.015 |
aus · f32 |
122.585 | 0.023 |
Even cold, the two implementations do not converge for any dtype at 600 s.
audio_samples_io is 4.5× faster than hound for i16, 1.9× for i32, and 3.3× for f32.
The storage device is fast enough that hound's per-sample CPU loop remains the binding constraint even in cold-read conditions: storage bandwidth is no longer the equaliser.
i16 continues to show the largest hound disadvantage: 280 ms for hound vs 62.2 ms for audio_samples_io (4.5×).
The structural reason is unchanged from the warm-cache case: hound's per-sample loop cannot keep up with the storage interface's delivery rate for the narrow i16 type.
At short durations (1–5 s), both libraries are operating in the low-millisecond range where file-open latency and OS scheduling noise dominate, and results are noisier for all dtypes.
Discussion
Why reads diverge: implementation-level analysis
The large read speedup for audio_samples_io is a direct consequence of how each library moves bytes from disk into memory, and examining the source code of both confirms this precisely.
hound's .samples::<T>() iterator calls Sample::read() once per sample (read.rs L733–736, hound v3.5.1).
Each Sample::read() call dispatches through the ReadExt trait to a type-specific function (read_le_i16(), read_le_i32(), and so on), which in turn calls read_into() in a per-byte loop (read.rs L119–193, hound v3.5.1).
Even with BufReader absorbing the underlying syscall overhead, every sample still requires multiple function-call layers, a bitwise assembly step, and a type conversion.
Over a 600 s i16 file (approximately 26.5 million samples), this amounts to 26.5 million iterations of that stack.
audio_samples_io's non-streaming path takes a fundamentally different approach.
The entire file is loaded into memory via BufReader::read_to_end() or memory-mapped with a sequential read-ahead hint (wav/wav_file.rs, lines 312–325, audio_samples_io v0.3.2).
For aligned data, samples are then made available via an unsafe core::slice::from_raw_parts reinterpretation of the raw byte slice (wav/data.rs, lines 83–85, audio_samples_io v0.3.2): no copy, no per-sample conversion, just a type-level assertion that the bytes are already in the right format.
When the in-file type matches the requested output type (S == T), an additional unsafe mem::transmute skips even the Vec conversion step (wav/data.rs, line 201, audio_samples_io v0.3.2).
In the common case the entire 'decode' step reduces to a single pointer cast followed by a bounds check.
Safety boundary. The from_raw_parts path is entered only after the WAV header has been validated against four conditions: the declared sample format matches the requested Rust type S; the bit depth and block alignment are consistent with S; the data is little-endian (mandatory in standard WAV); and the buffer meets the alignment requirements of S. A mismatch on any of these returns an error before the unsafe block is reached. The mem::transmute path additionally requires S == T at the type level, enforced by the compiler. Malformed WAVs that pass header validation but carry corrupt data will produce garbage samples. The same guarantee that hound provides, since neither library checksums sample data.
The streaming path retains most of this advantage.
audio_samples_io's read_frames_into issues a single read() call for all bytes of the requested chunk (wav/streaming.rs, line 445, audio_samples_io v0.3.2), writes them into a reused internal Vec<u8> buffer, and then converts in bulk using chunks_exact(2).map(...) or chunks_exact(4).map(...): one pass through the byte slice at the cost of a single iterator chain.
hound's streamed path is identical to its bulk path from an internal standpoint: the same per-sample iterator, called the same number of times regardless of what chunk size the caller imposes.
Why writes diverge for i32 and f32
Both libraries ultimately write through a BufWriter, and the BufWriter coalesces per-sample calls before they reach the OS.
hound's write_sample() dispatches through Sample::write_padded() on every call (write.rs L429–437, hound v3.5.1), but each call writes only a small number of bytes to the internal write buffer; the kernel only sees the batched flushes.
audio_samples_io serialises a whole AudioSamples chunk in one pass and writes it with a single write_all().
The difference is the number of function-call layers per byte written, not the number of syscalls.
The 2.5× advantage for i32 and 2.1× for f32 at 10 s reflects exactly this: the server's storage can drain the BufWriter quickly enough that the per-sample dispatch in hound becomes the bottleneck, while audio_samples_io's bulk write_all amortises that cost.
The criterion benchmark uses hound's get_i16_writer (SampleWriter16) path for all i16 writes, both bulk and streamed, which pre-allocates an internal buffer and flushes with a single write_all(), closely mirroring what audio_samples_io does.
For i32 and f32, hound has no equivalent optimised writer, so those types always use write_sample per sample.
The i16 write results therefore compare each library's best available path (≈ 1.05× at 10 s); the i32/f32 results compare audio_samples_io's bulk serialisation against hound's only available path for those types (2.5× and 2.1× respectively).
Predictability as an independent result
Beyond mean latency, the cv values carry their own information.
audio_samples_io's read times have standard deviations consistently much smaller than hound's at short and medium durations (e.g. ≈ 78× smaller at 60 s for i16, where hound's σ is 0.471 ms vs audio_samples_io's 0.006 ms, derived from avg × cv); at 600 s, where both implementations are DRAM-bound, the ratio narrows to ≈ 4×.
This follows from the implementation: a path that performs one bulk read and one pointer cast has far fewer opportunities to accumulate scheduling jitter than one that iterates millions of times.
hound's cv climbs at longer durations (e.g. cv 0.103 for i32 at 30 s vs 0.050 for audio_samples_io), reflecting the probabilistic accumulation of interrupt-induced pauses over a long per-sample iteration loop.
In latency-sensitive applications (real-time transcription, live DSP, audio pipeline inference), tail latency is often the binding constraint rather than average throughput. In audio, 'real-time' typically means completing processing within a fixed buffer period: for example, a 1,024-sample buffer at 44,100 Hz gives approximately 23 ms per callback, and a 256-sample buffer gives 5.8 ms. audio_samples_io's consistently lower cv means its worst-case times stay closer to its average, making it easier to reason about under real-time deadlines regardless of which buffer size defines the constraint.
Streamed write chunk size as an ablation of call overhead
The chunk-size sweep in the streamed write condition reveals an asymmetric picture across dtypes.
For i32 and f32, audio_samples_io is faster at every chunk size tested and the advantage grows monotonically with chunk size, consistent with amortising the fixed per-call overhead of write_frames over more data.
For i16, the picture is more nuanced: at 512 samples audio_samples_io is slower (≈ 0.77× at 60 s), approximately parity at 1,024 samples, and faster from 4,096 samples upward (≈ 1.83× at 60 s).
This inversion at small chunk sizes reflects the interaction between audio_samples_io's per-call overhead and hound's SampleWriter16 optimised path, which is particularly efficient for i16 at small write granularity.
The implication for practitioners is that audio_samples_io's write advantage is not fixed: it grows with processing block size for i32 and f32, and for i16 requires at least a 4,096-sample chunk to materialise. Applications already operating on large audio buffers will benefit most.
The small-signal noise floor
Results at 1 s and 5 s durations, particularly for streamed writes, exhibit qualitatively different behaviour from longer durations.
Mean times fall in the sub-millisecond to low-millisecond range, where the resolution of std::time::Instant on Linux, OS scheduling quanta, and file-open/close overhead each constitute a non-negligible fraction of the measured interval.
Several 1 s streamed write configurations show cv values of 0.5–2.0, and individual iterations can be an order of magnitude above the mean.
At these scales the benchmark is as much a measurement of OS scheduler behaviour as of library throughput.
The results demonstrate that both libraries can handle short files quickly, but any ranking at this granularity would require pinned CPU affinity, disabled frequency scaling, and clock sources with sub-microsecond resolution to be reliable.
Limitations
Single machine, single filesystem. All measurements were taken on the server described in the Test Environment section.
Because Criterion's warmup phase precedes measurement, read benchmarks reflect page-cache-warm performance at short and medium durations, and are DRAM-bandwidth-bound at long durations where the file exceeds the LLC.
Write results should be interpreted in light of the server's filesystem and storage configuration (ext4, rw,relatime, QEMU virtual disk; see Test Environment); absolute write times will differ on different filesystems or compression settings, though the relative ordering between libraries should be more stable.
Whether the relative ordering between libraries changes on spinning disk or network-attached storage is not tested here.
Page-cache warmth and LLC effects. Criterion's warmup phase brings file-sized working sets into the page cache before measurement begins.
For files smaller than the server's LLC, warmup also brings the working set into the LLC itself, and audio_samples_io's throughput at those sizes reflects L3 bandwidth rather than DRAM bandwidth.
The headline speedup figures (up to 105×) should therefore be understood as LLC-warm figures for appropriately-sized files.
For files larger than the LLC, performance is DRAM-bound and speedup figures are lower (8.6× for i16 at 600 s, 3.3–3.4× for i32, 2.5× for f32).
The cold-cache benchmarks measure the storage-bound case directly; on this server, storage is fast enough that hound's CPU bottleneck remains the dominant constraint even cold, so the convergence to near-parity observed on slower SATA storage does not occur here.
Mono and stereo, but not surround. Both mono (1-channel) and stereo (2-channel) signals were benchmarked.
Speedup profiles are essentially identical across the two channel counts, suggesting audio_samples_io's deinterleaving path adds negligible overhead at these file sizes.
Whether the same holds for surround formats (5.1, 7.1), where the interleave stride is larger, remains untested.
Fixed sample count across all durations. Criterion collects 100 samples per benchmark regardless of signal duration. Short benchmarks accumulate more inner iterations per sample (Criterion scales automatically), while long benchmarks may achieve only one iteration per sample. The 600 s streamed write results (CV 4–14%) are based on fewer total timed iterations than shorter durations and should be treated as indicative; a dedicated long-duration write experiment with tighter OS noise control would be needed to draw strong conclusions at that scale.
hound's write path varies by dtype. For i16, the benchmark uses hound's SampleWriter16 path (get_i16_writer), which pre-allocates an internal buffer and flushes with a single write_all (hound's most efficient write API).
For i32 and f32, no equivalent optimised writer exists in hound, so those dtypes use the standard write_sample per-sample path.
The i16 write comparison is therefore already between each library's best available path; the i32/f32 results reflect hound's only available path for those types.
Contextualising the read numbers
The warm-cache read speedup (2.5–105× depending on dtype, duration, and LLC fit) is a real measurement, but it measures specific scenarios: either the file fits in the LLC (high speedup) or the file is larger than the LLC but still DRAM-resident (moderate speedup).
Both are relevant for repeated-access workloads: multi-epoch training loops, hot file caches, or any pipeline that reads the same files many times.
For those workloads the advantage is large and architecturally significant: 10,000 ten-second i16 files read from a warm cache take roughly 41 seconds with hound and about 1.1 seconds with audio_samples_io at the 36× speedup measured at 10 s.
For workloads that read each file once from a large dataset, the cold-cache numbers are the honest baseline.
On this server, storage is fast enough that hound's per-sample CPU loop is the bottleneck even cold: audio_samples_io is 1.9–4.5× faster across all dtypes at 600 s cold.
Unlike on slower SATA storage, the gap does not close at longer durations.
Any benchmark that cites only LLC-warm figures without qualifying the LLC size is overstating the practical advantage for single-pass dataset work.
Practical implications
Reads. For workloads where files are read repeatedly or the working set fits in the LLC, audio_samples_io's warm-cache advantage is large enough to matter and should be the deciding factor.
For cold, single-pass reads, audio_samples_io remains faster across all dtypes on this server (4.5× for i16, 1.9× for i32, 3.3× for f32 at 600 s cold): storage is no longer the equaliser here, because the server's storage is fast enough that hound's CPU bottleneck is still exposed.
Streaming reads. The advantage transfers fully to the streaming path at every chunk size tested. Applications can choose processing block sizes based entirely on algorithmic or latency requirements without any I/O throughput penalty.
Writes. At 10 s the advantage is modest for i16 (≈ 1.05×) and more meaningful for i32 and f32 (≈ 2.5× and ≈ 2.1×); at longer durations the advantage grows substantially. For streamed writes, the advantage is chunk-size dependent: audio_samples_io is slower than hound for i16 at very small chunks (512 samples) but faster from 4,096 samples upward across all dtypes.
API and ergonomics
Performance aside, the two libraries have meaningfully different APIs, and the ergonomics argument deserves equal weight in a practical decision.
hound models a WAV file as a spec plus a flat iterator of interleaved samples.
To read a file you must inspect the header, dispatch on bit depth and sample format, and collect into a Vec<T> with no channel structure.
Channel interleaving is your responsibility to untangle.
On the write side, WavSpec must be fully specified before writing starts, and finalize() should be called explicitly: although WavWriter's Drop implementation attempts finalisation on drop, any I/O error during that drop-time finalisation is silently swallowed, so explicit finalize() is the only way to surface a failure to the caller.
audio_samples_io inverts this.
read::<_, i16>(path) is a single call that returns an AudioSamples<i16>, a channel-aware struct that carries its own sample rate, frame count, and channel count.
There is no manual header dispatch, no interleaved Vec to reinterpret, and for the one-shot write path no finalize() step: the write is completed before write() returns.
The sample_rate! macro produces a NonZeroU32 at compile time, making a zero sample rate a build error rather than a runtime panic.
Even before reaching for advanced features (resampling, filtering, spectral transforms), the core API is genuinely less error-prone for audio work.
hound has the smaller API surface; audio_samples_io encodes more format invariants for users who want structured audio data.
Smaller surface area is not the same as easier to use correctly: with hound the user is responsible for more decisions (header dispatch, interleaved layout, finalize()), but that trade-off is entirely reasonable when the priority is a minimal dependency count and a simpler mental model.
The broader ecosystem
Loading and saving audio is rarely the end goal. In practice, audio data is read, processed, and written, and the gap between hound and audio_samples_io widens considerably once you account for what happens in between.
hound stops at the file boundary. Once you have a Vec<i16>, any further processing requires separate crates: resampling, channel mixing, filtering, windowing, spectral analysis, and so on. Each of those crates has its own types, its own channel and sample-rate conventions, and its own error surface. The user is responsible for keeping everything consistent.
audio_samples is designed to be the representation you carry through the whole pipeline. The same AudioSamples<T> struct that audio_samples_io returns can be passed directly to the library's resampling, filtering, spectral transforms, parametric EQ, and VAD routines without any conversion or unwrapping. Spectral analysis is handled through wrapper functions that extract the internal ndarray representation and pass it to the spectrograms crate, which was spun out of audio_samples because it could stand alone as a general-purpose library. From the caller's perspective it is still a single API; the split is an implementation detail. Sample rate and channel count travel with the signal throughout, so there is no opportunity for a mismatch between what a processing function receives and what the format implies.
For projects that will do any meaningful audio work, this matters more than the I/O benchmark numbers. It is not just that audio_samples_io reads faster; it is that the loaded audio arrives in the right type to continue working with, across a growing ecosystem of crates that all share the same representation, under the same type-safety guarantees, without any conversion layer between them. The dependency count discussed above should be read in this light: crates like rayon and ndarray are there to support the processing capabilities, not the I/O path, and a project that would pull them in independently for its own work gets them for free.
Dependencies
hound v3.5.1 has zero production dependencies. Any project that depends on hound compiles exactly hound and nothing else.
audio_samples_io v0.3.2 (with the bare-bones feature on audio_samples v1.0.11 and the wav feature on audio_samples_io) brings a moderate but well-motivated tree. The direct production dependencies of audio_samples_io itself are: bytemuck (zero-copy type casting), memmap2 (memory-mapped files, which requires libc), ndarray, non-empty-iter, non-empty-slice, and thiserror. The audio_samples crate adds: bytemuck, i24 (24-bit integer type, which transitively requires ndarray and num-traits), ndarray, non-empty-iter, non-empty-slice, num-complex, num-traits, and thiserror.
Every dependency in this list has a clear role. bytemuck and memmap2 back the fast zero-copy I/O path. ndarray is the storage layer for AudioSamples<T>. thiserror handles error types. num-traits arrives transitively via i24, which enables 24-bit integer support. non-empty-iter and non-empty-slice are what enforce the non-empty audio and non-zero channel guarantees at the type level. None of these are incidental. Notably, the heavier optional capabilities of audio_samples (parallel processing via rayon, plotting support) are not present under bare-bones; they are behind separate feature flags and incur no compile cost unless explicitly enabled. When the spectral transform feature is enabled, spectrograms enters the graph as an additional dependency; it is optional and incurs no cost when not used.
All of the crates listed are among the most-downloaded and actively maintained in the Rust ecosystem. bytemuck, ndarray, and thiserror in particular are widely used in Rust numerical computing, so the marginal cost of adding audio_samples_io is often lower than the raw count implies.
hound's zero-dependency position remains a genuine advantage in specific contexts: embedded or no_std targets, environments with strict supply-chain audit requirements, or projects where compile time is tightly budgeted. For general-purpose audio work on a standard target, the trade-off is whether the listed crates are acceptable given the performance and ergonomic gains on the other side, and for Rust projects already doing numerical or audio processing work, several will already be in the graph.
Future work
Several extensions would strengthen or broaden these findings.
A surround-format sweep (5.1, 7.1) would test whether audio_samples_io's SIMD deinterleaving path remains cost-free as the channel count grows, and would also exercise the audio_samples_io streamed multi-channel path which is not covered here.
Profiling hound's read path under a sampling profiler (e.g. perf record with --call-graph dwarf) would confirm whether the bottleneck is the trait-dispatch iteration, the per-byte ReadExt calls, or the BufReader refill logic, and would guide any targeted optimisation of hound itself.
The cold-cache i16 result (where hound cannot saturate the storage interface despite the CPU being nominally idle) makes the CPU-side bottleneck hypothesis particularly worth verifying.
Finally, repeating the cold-cache read benchmarks on NVMe storage (where sequential read bandwidth exceeds 3,000 MB/s) would test whether hound's CPU bottleneck on i16 persists at higher bus speeds, or whether the gap closes once the storage layer is fast enough to keep the per-sample pipeline continuously fed.
Conclusion
Both libraries solve the same problem (reading and writing WAV files in Rust), but they do so from fundamentally different positions.
hound is a well-established library with a long track record in the Rust ecosystem. Its API is minimal and its behaviour is predictable, but 'minimal' is not the same as simple to use correctly: the user is responsible for manual header dispatch, interpreting flat interleaved output, and a finalize() call whose omission causes any finalisation error to be silently swallowed by the Drop implementation rather than returned to the caller. Its one unambiguous advantage is zero transitive dependencies, which carries real weight in environments where the dependency graph is audited or constrained.
audio_samples_io takes a structurally different position. Its read path (a bulk memory load followed by a pointer cast) is inherently faster than any per-sample iterator, and the benchmarks confirm it: up to 105× faster on LLC-warm reads, 2.5–8.6× for DRAM-warm reads at long durations, and 1.9–4.5× faster on cold reads, because on this server's fast storage hound's per-sample CPU loop remains the bottleneck even without a page-cache advantage. The write advantage is measurable across all dtypes at medium-to-large chunk sizes: ≈ 2.5× and ≈ 2.1× for i32 and f32 at 10 s bulk; ≈ 1.83×, ≈ 2.10×, and ≈ 1.78× for i16, i32, and f32 at 600 s streamed with 4,096-sample chunks. Beyond raw performance, the API is easier to use correctly: a single read call returns a typed, channel-aware struct with sample rate and frame count embedded; writes complete atomically; and invalid audio is structurally harder to construct by accident. With the bare-bones feature, the dependency tree is moderate and every crate in it has a clear, specific purpose; the heavier optional capabilities (parallel processing, plotting) are behind separate feature flags and compile only when requested.
The warm-cache speedup figures deserve context. LLC-warm figures (up to 105×) apply when the file fits in the processor's LLC, typical for repeated access to smaller files. DRAM-warm figures (2.5–8.6×) apply when the file is larger than the LLC but still in-memory. Cold figures (1.9–4.5×) apply to single-pass reads on fast storage. A benchmark that cites only the highest figures without qualifying the cache scenario overstates the practical advantage for large single-pass datasets, though on NVMe-class storage the cold figures would likely remain meaningful.
For new Rust projects doing audio work, audio_samples_io is the stronger default: faster across reads at every measured cache scenario, faster writes across all dtypes at medium-to-large chunk sizes, less error-prone by construction, and the dependency overhead is manageable with feature flags. hound remains the right choice when zero transitive dependencies is a hard requirement or when integrating with an existing hound-based codebase.