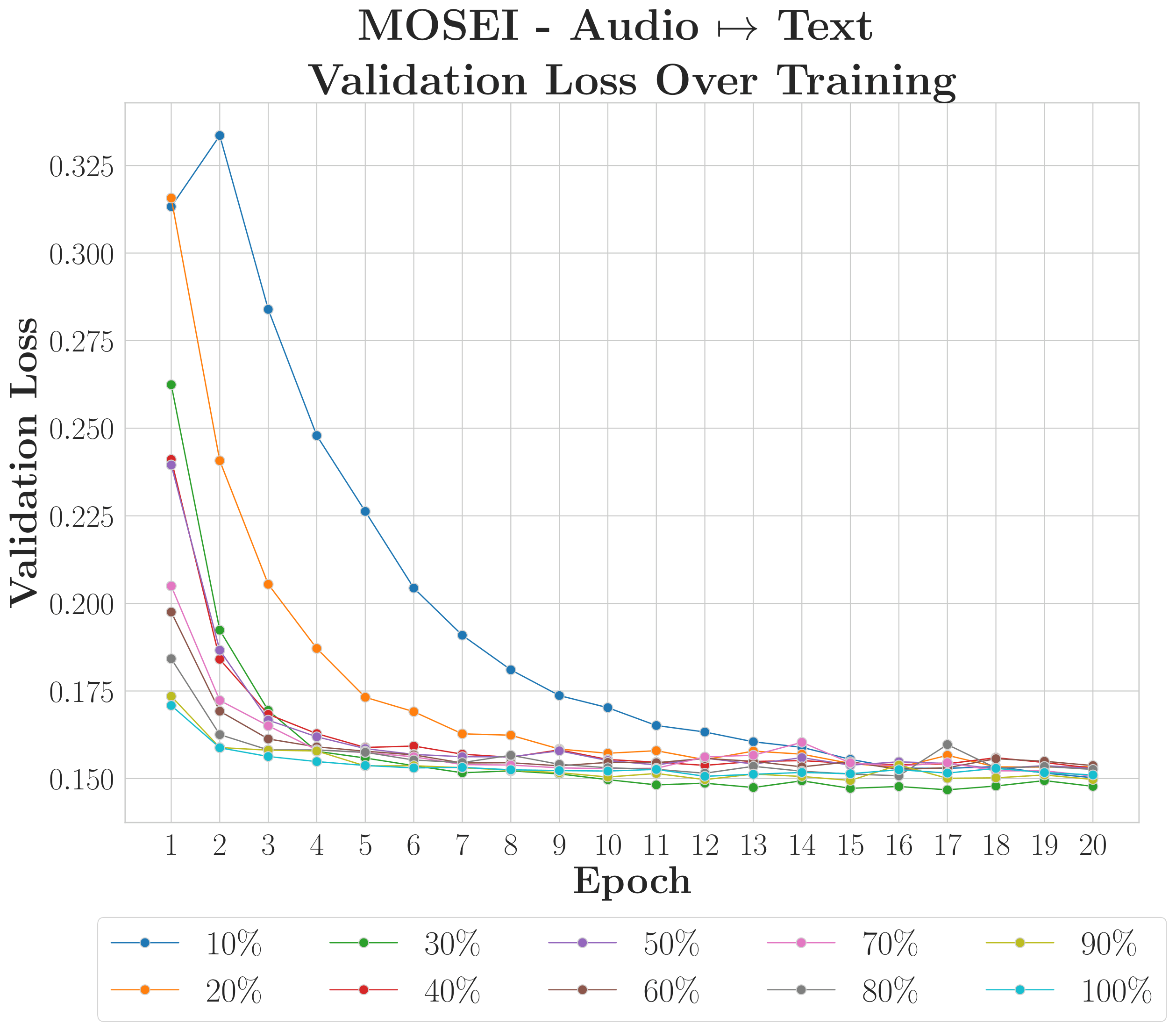
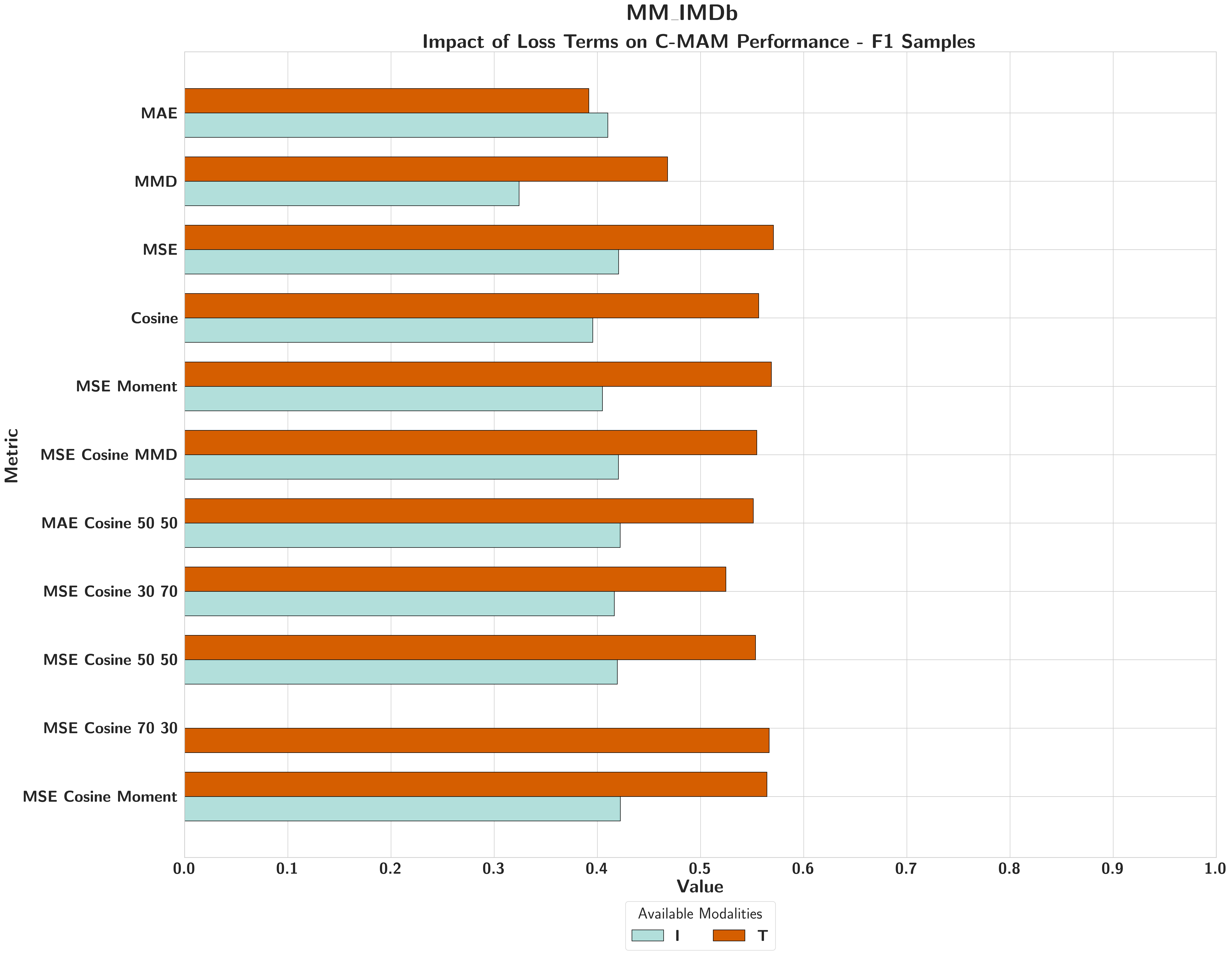
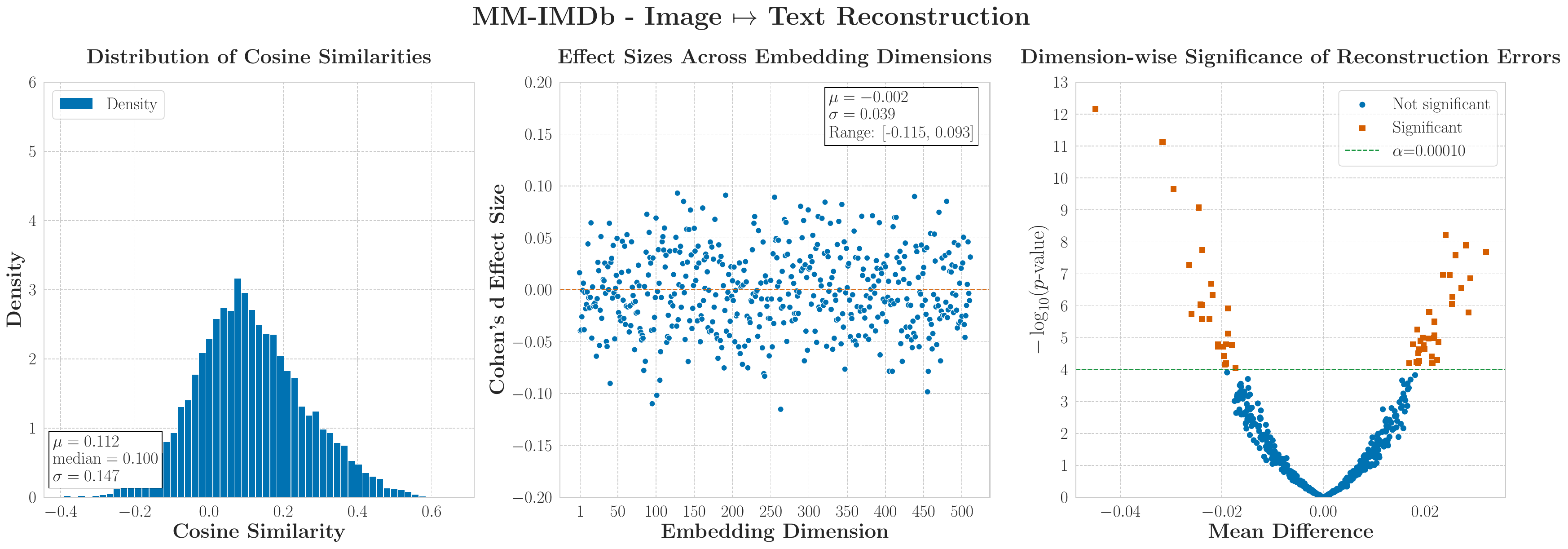
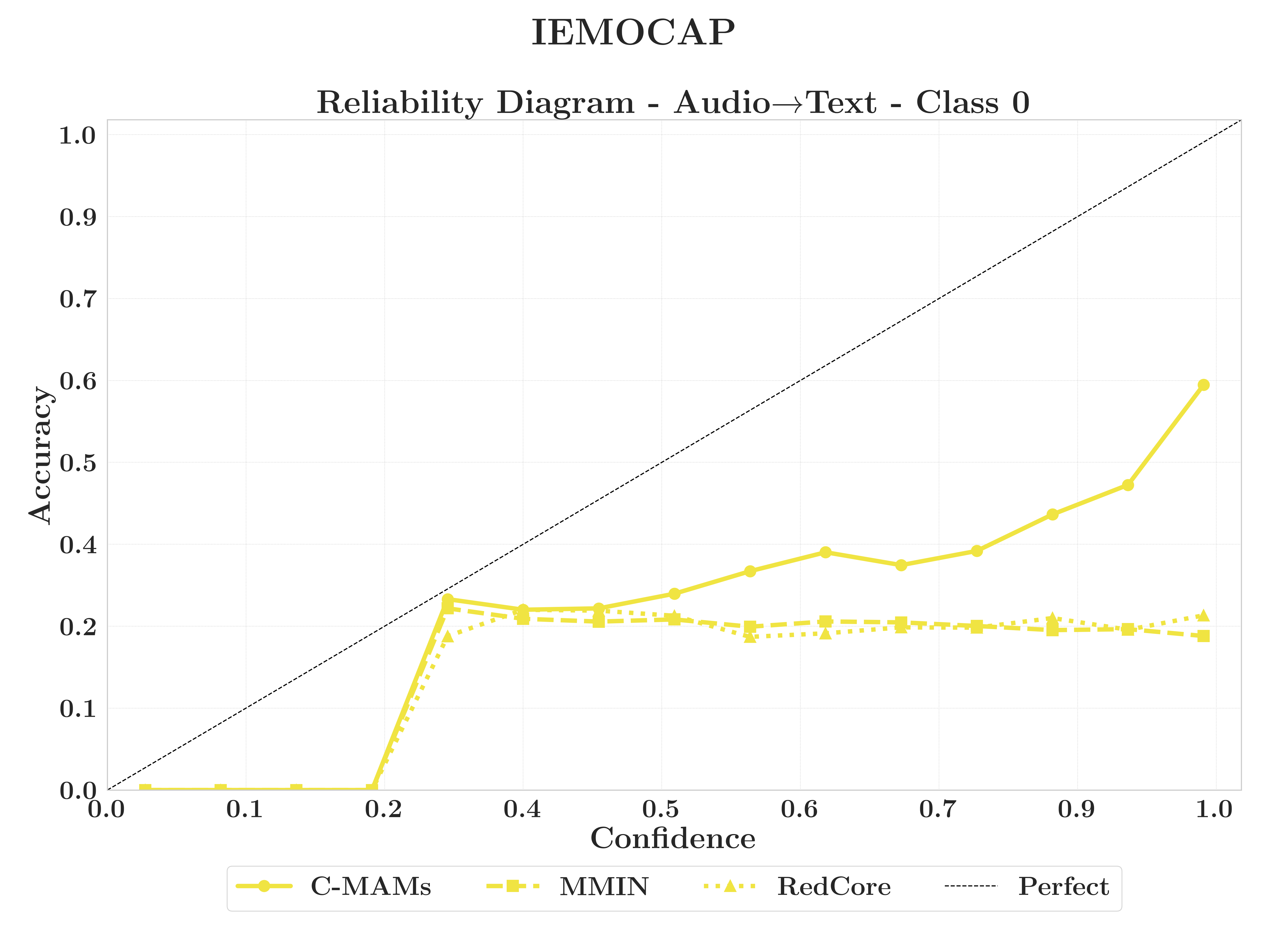
Multimodal models assume joint availability of all modalities. In practice, this assumption is frequently violated.
Modalities may be absent
Sensor failure, privacy constraints, and bandwidth limitations.
Behaviour changes
Performance degradation is not uniform. Confidence and calibration may shift.
Retraining is often impractical
Systems may already be deployed or data unavailable.
When modalities are absent, behaviour changes, and retraining is impractical, how can these effects be understood and handled?
Evaluation
Evaluating Multimodal ModelsEvaluation
Full-Modality Performance
Baseline: all modalities present at inference
The ceiling against which robustness is measured
Modality Contribution
Average marginal utility across modality subsets
Estimated via MM-SHAP
Modality Dependence
Effect of removing a modality
Estimated via ablation
RQ1: Modality Absence and Behavioural Degradation
RQ1: Modality Absence and Behavioural DegradationRQ1
Research question
How and to what extent does model performance change when an entire modality is unavailable at inference time, and how reliably can this change be anticipated?
Under Review with Information Fusion
Multimodal models are not evaluated properly.
Research answer
Degradation is substantial, asymmetric, and partially predictable; attribution signals do not reliably reflect functional dependence, and modality reliance emerges early in training.
RQ1: Results
RQ1: Modality Absence and Behavioural DegradationRQ1 Results
RQ1: Key findings
Attribution under full input does not reliably predict removal impact; masking strategy directly shapes what robustness is measured; and modality dependence is detectable during training but not from validation metrics alone.
RQ1.1 — Contribution vs Dependence
RQ1.2 — Masking
RQ1.3 — Training-Time Indicators
Dataset
Modality
Cohen's d
p-value
Better
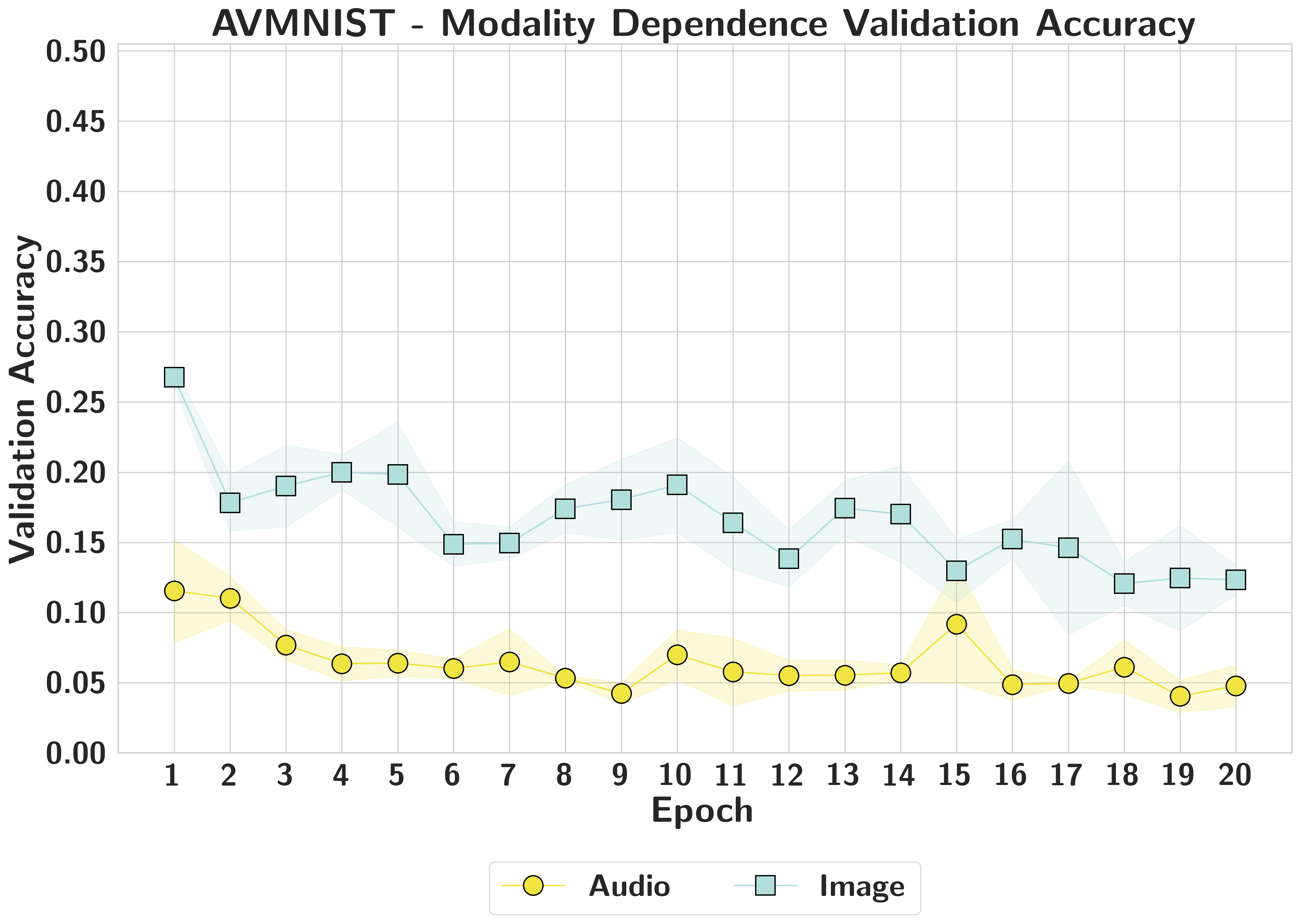
AVMNIST
Audio
−3.34
0.014
Zero
↳
Image
−3.33
0.014
Zero
MM-IMDb
Text
-8.26
0.002
Zero
↳
Image
−0.87
0.134
n.s.
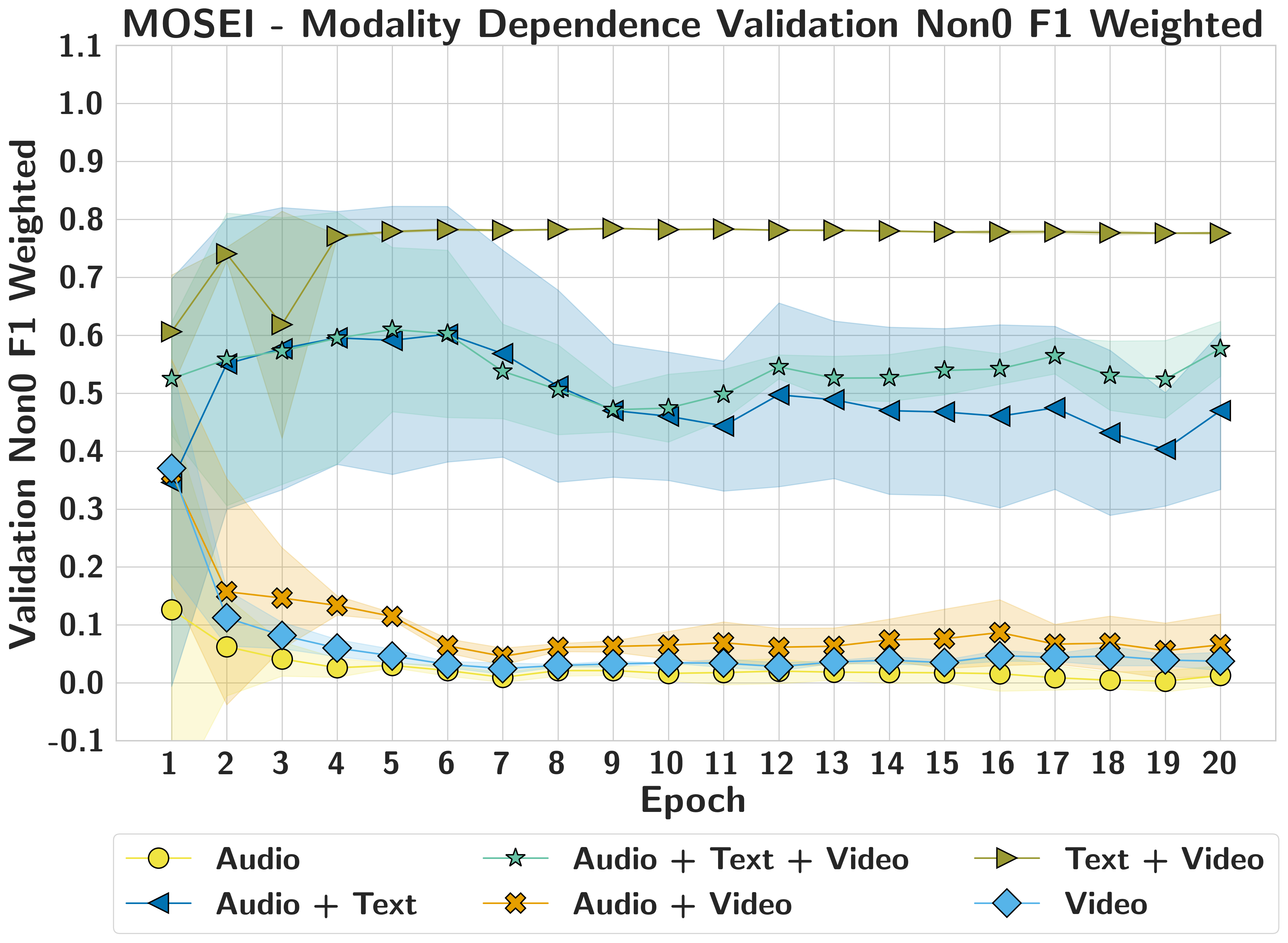
MOSEI
Audio
+3.54
<0.05
Noise
↳
Video
+1.85
<0.05
Noise
↳
Text
+4.22
<0.05
Noise
Negative d = zero better; positive d = noise better. All significant effects are large (|d|≥1.85).
What this shows
Three independent probes. Each reveals what the others miss.
No single metric captures the full picture.
Run absence tests. Attribution proxies are not enough.
Why it matters
Masking strategy is a design decision. Validate it empirically.
Training trajectories give early warning before deployment failures.
Attribution-based robustness estimates are unreliable.
Transition
Fragility is established.
Can we fix it? Yes, we can!
RQ2: Post Hoc Modular Reconstruction
RQ2: Post Hoc Modular ReconstructionRQ2
Research question
To what extent can a modular, lightweight, and post-training feature reconstruction approach mitigate performance degradation caused by fully missing modalities during multimodal model inference?
Published in ACM Transactions on Intelligent Systems and Technology (2025)
Modular post-hoc reconstruction recovers from missing modalities.
Research answer
C-MAMs recover a substantial fraction of lost performance with shallow networks on limited data; recovery correlates with inter-modality structure, not reconstruction geometry.
RQ2: Results
RQ2: Post Hoc Modular ReconstructionRQ2 Results
RQ2: Key findings
Reconstruction quality is bounded by encoder representational structure, not loss complexity or geometric precision: C-MAMs are data-efficient, loss-insensitive, frozen-encoder-friendly, and constrained where encoder alignment fails.
RQ2.1 — Training Efficiency
RQ2.2 — Impact of Loss Function
RQ2.3 — To Train or Not to Train
RQ2.4 — Geometry vs Performance
RQ2.5 — Encoder Alignment
MOSEI: Mean Δ vs Frozen Baseline (Has0 Acc & Has0 F1 Weighted)
Condition
Random Init Δ
Fine-tuned Δ
A
−0.027
+0.040
V
+0.011
+0.045
T
−0.014
−0.002
AV
+0.011
+0.006
AT
−0.007
−0.005
VT
+0.005
+0.002
Δ = difference vs frozen encoder. Negative = worse than frozen. Random init harms A and T; fine-tuning helps A and V but is neutral/negative for T.
Reconstruction Error: MAE / MSE (Table 5.12)
Model & C-MAM
MAE
MSE
KS: Audio → Video
3.82
32.79
KS: Video → Audio
0.69
1.32
MM-IMDb: Image → Text
0.30
0.16
MM-IMDb: Text → Image
0.29
0.14
UTT-Fusion: AT → Video
0.07
0.009
UTT-Fusion: Audio → Text
0.23
0.19
KS audio→video peaks at MSE=32.79. This is a consequence of near-orthogonal encoder spaces, not decoder choice.
Contrastive Information Analysis (Table 5.13)
Dataset
MI Red.
Dominance
Cosine
KL Div.
AVMNIST
Weak
Image
0.006
0.85
Kinetics-Sounds
Strong
Video
−0.04
2.95
MOSEI
Moderate
Text
0.28–0.38
0.34
High KL + near-orthogonal cosine = strong contrastive behaviour. In KS, video and audio encode largely distinct, conflicting information. The ceiling is set by the encoders, not the C-MAM.
Loss complexity and fine-tuning are not worth the cost.
Transition
Recovery is possible.
But is everything behaving correctly?
RQ3: Behavioural Fidelity of Reconstruction
RQ3: Behavioural Fidelity of ReconstructionRQ3
Research question
How do reconstructed modality embeddings affect the decision behaviour of multimodal models relative to missing-modality baselines, and how do different reconstruction methods compare in information recovery, calibration behaviour, and class-conditional predictive structure?
Under Review with TBD
Under proper scrutiny, simple reconstruction beats complex SOTA.
Research answer
Reconstruction improves behaviour but geometric fidelity and calibration diverge systematically; lightweight decoders can achieve stronger behavioural stability than high-capacity alternatives.
RQ3: Results
RQ3: Behavioural Fidelity of ReconstructionRQ3 Results
RQ3: Key findings
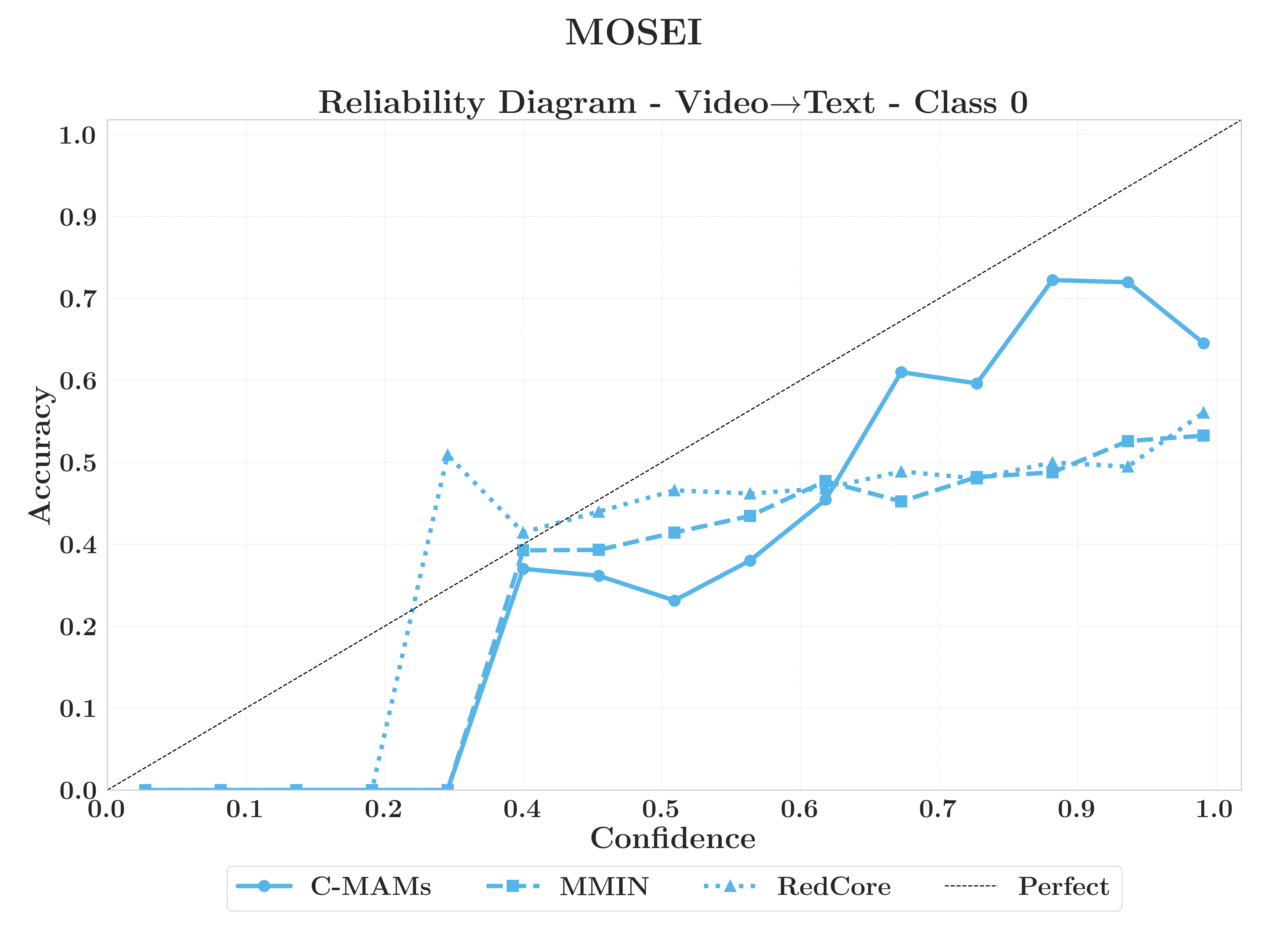
C-MAMs more frequently reach the information-theoretic recovery limit, provide superior minority-class generalisation over higher-capacity models, and maintain better confidence calibration under modality absence.
RQ3.1 — Conditional Variance
RQ3.2 — Complexity vs Generalisation
RQ3.3 — Calibration
Mapping
Model
RMSE
√Var(Y|X)
Δ
H1
V→A ★
C-MAM
0.139
0.116
+0.024
Yes
MMIN
0.201
0.122
+0.079
No
RedCore
0.824
0.782
+0.042
Yes
TV→A ★
C-MAM
0.137
0.116
+0.021
Yes
MMIN
0.158
0.117
+0.040
Yes
RedCore
0.887
0.753
+0.134
No
IEMOCAP (★ = H1 satisfied). C-MAM: 5/6 saturated. MMIN: 2/6. RedCore: 1/6. RMSE proximity to √Var(Y|X) is the criterion. Not absolute RMSE.
Mapping
C-MAM
Neutral Recall
MMIN
Neutral Recall
RedCore
Neutral Recall
H2.1
H2.2
A→V
0.477
0.330
0.091
Yes
Yes
AT→V
0.610
0.588
0.441
Yes
Yes
V→A
0.116
0.047
0.009
Yes
Yes
AV→T
0.429
0.408
0.242
Yes
Yes
T→A
0.422
0.432
0.378
Yes
Yes
TV→A
0.467
0.541
0.438
No
Yes
MSP-IMPROV. H2.1: C-MAM ≥95% parity in 5/6 mappings. H2.2: RedCore underperforms MMIN on neutral recall in all 6/6 mappings.
What this shows
C-MAMs lead on recovery, minority recall, and calibration.
Capacity does not predict bound saturation.
Capacity can harm confidence.
Why it matters
Miscalibrated confidence is a liability.
C-MAMs keep confidence honest.
Calibration belongs in reconstruction evaluation.
Transition
Centralised robustness holds.
Does it survive federated deployment?
RQ4: Federated and Decentralised Reconstruction
RQ4: Federated and Decentralised ReconstructionRQ4
Research question
Can modular reconstruction methods be adapted effectively for robust multimodal learning within incongruent federated systems with heterogeneous modality availability and local data access constraints?
Federated multimodal models can be trained under modality incongruence.
Research answer
FedC-MAMs improve client-level robustness where degradation is meaningful and reduce communication cost relative to monolithic baselines; they are scalable and behaviourally effective.
RQ4: Results
RQ4: Federated and Decentralised ReconstructionRQ4 Results
RQ4: Key findings
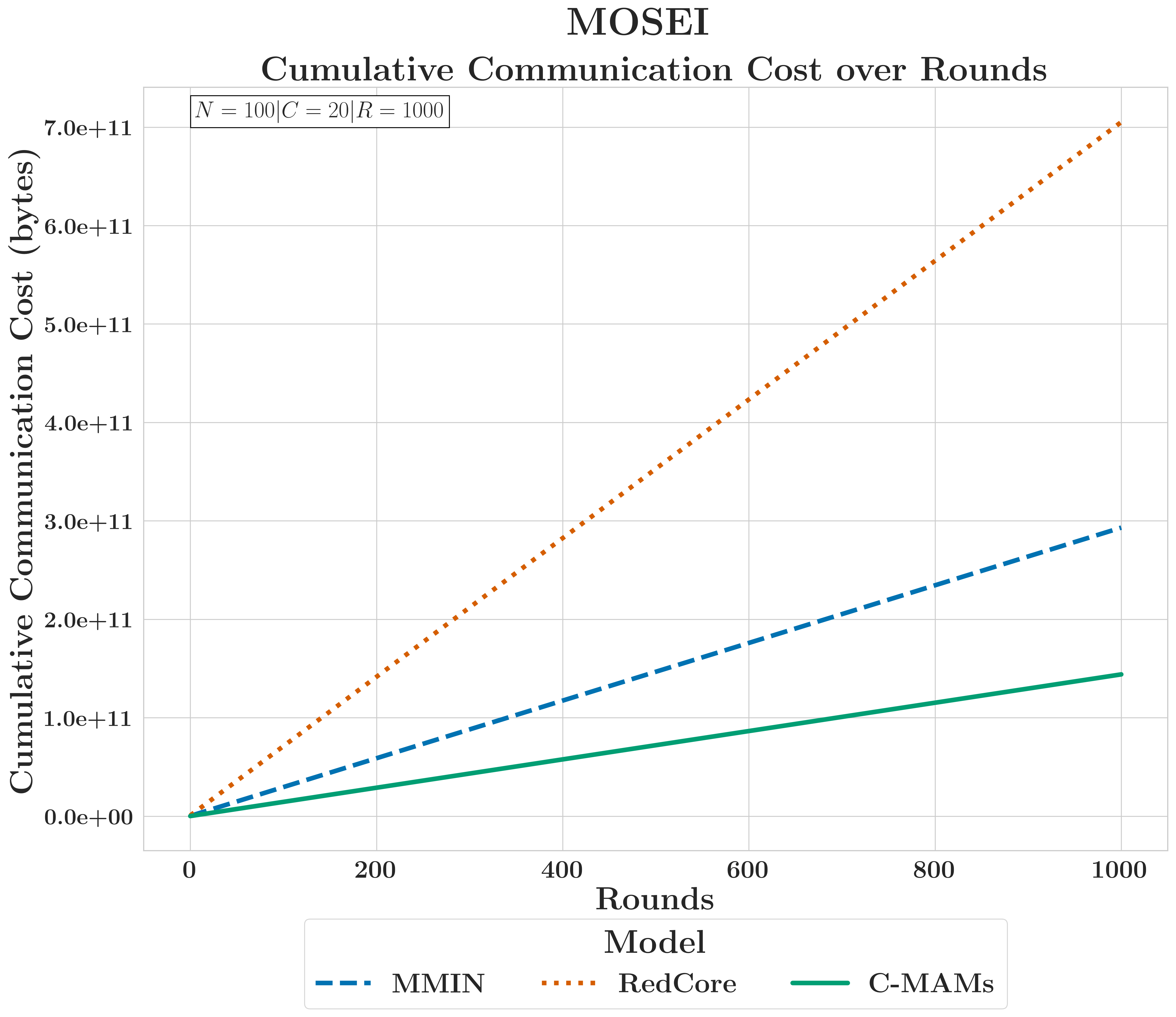
FedC-MAMs restore substantial performance for modality-limited clients and consume ~50% of MMIN's energy and ~17% of RedCore's; modularity achieves both robustness and communication efficiency together.
RQ4.1 — Performance Under Incongruency
RQ4.2 — Communication Efficiency
MOSEI: Has0 Accuracy
Client
Base
FedC-MAMs
Δ
A only
0.251
0.693
+0.442
V only
0.343
0.661
+0.318
AV
0.403
0.668
+0.265
T only
0.667
0.730
+0.063
AT
0.740
0.763
+0.023
TV
0.717
0.751
+0.034
MSP-IMPROV: F1 Weighted
Client
Base
FedC-MAMs
Δ
A only
0.362
0.396
+0.034
V only
0.290
0.427
+0.137
AV
0.500
0.502
+0.002
T only
0.294
0.465
+0.171
AT
0.570
0.442
−0.128
TV
0.419
0.593
+0.174
What this shows
Modular reconstruction works in federated settings.
Gains scale with degradation severity.
Not unconditional: reconstruction can hurt when degradation is already low.
Why it matters
Robustness and efficiency together. Not a trade-off.
Selective aggregation cuts cumulative energy by 50–83%.
Practical federated robustness without end-to-end overhead.
Thesis Contributions
Thesis: ContributionsConclusion
Thesis claim
Missing-modality robustness is a behavioural, architectural, and systems-level design challenge that can be mitigated post-training through modular reconstruction without retraining or architectural modification.
Thesis conclusionPractical robustness to missing modalities can be achieved through simple, modular, post-training reconstruction that respects deployed architectures and scales naturally across centralised and decentralised environments.
Research Questions: Resolved
RQ1
How and to what extent does model performance change when an entire modality is unavailable, and how reliably can this be anticipated?
Degradation is substantial, asymmetric, and partially predictable; attribution signals do not reliably reflect functional dependence, and modality reliance emerges early in training.
RQ2
To what extent can modular post-training reconstruction mitigate missing-modality performance degradation?
C-MAMs recover a substantial fraction of lost performance with shallow networks on limited data; recovery correlates with inter-modality structure, not reconstruction geometry.
RQ3
How do reconstructed embeddings affect model behaviour, and how do methods compare in fidelity and calibration?
Reconstruction improves behaviour but geometric fidelity and calibration diverge systematically; lightweight decoders can achieve stronger behavioural stability than high-capacity alternatives.
RQ4
Can modular reconstruction be adapted for federated systems with heterogeneous modality availability?
FedC-MAMs improve client-level robustness where degradation is meaningful and reduce communication cost relative to monolithic baselines; they are scalable and behaviourally effective.
Publications
ContributionsContributions
Thesis Related
Directly related to the work presented in this thesis
Geraghty, Hines & Golpayegani. "Understanding the Relevancy of Modality Information in Multimodal Machine Learning". In: Modelling and Representing Context (MRC), ECAI.
Behavioural Failures in Multimodal Models Under Missing Modalities
Under Review
Journal paper. Under review with Information Fusion
Interpreting the Behaviour of Reconstructed Modalities
Under Review
Journal paper. Details to be confirmed
Reproducibility
All model, training, and evaluation code is public on GitHub.
Datasets are public and used as-released; same versions, same splits.
Only AVMNIST and Kinetics-Sounds need preprocessing: audio to spectrograms.
Non-Thesis Related
Not directly related to the work presented in this thesis
ACM MMSys (2026)
Geraghty, Golpayegani & Hines. "Audio Made Simple: A Modern Framework for Audio Processing". In: Proc. ACM Multimedia Systems Conference 2026, pp. 436–442. DOI: 10.1145/3793853.3799811
Springer Book Chapter (2026)
Geraghty et al. "Traffic Flow Breakdown Prediction for the M50 Motorway in Ireland". In: Transport Transitions: Advancing Sustainable and Inclusive Mobility. Springer Nature Switzerland, pp. 514–520.
IEEE Access: Journal (2022)
Golpayegani et al. "Intelligent Shared Mobility Systems: A Survey on Whole System Design Requirements, Challenges and Future Direction". In: IEEE Access 10, pp. 35302–35320. DOI: 10.1109/ACCESS.2022.3162848
ACM MMSys (2022)
Geraghty et al. "AQP: an open modular Python platform for objective speech and audio quality metrics". In: Proc. 13th ACM Multimedia Systems Conference, pp. 191–196. DOI: 10.1145/3524273.3532885
Looking Back and Looking Forward
Thesis: ConclusionLimitations & Future Work
Looking Back
There is always something more that could have been done
Controlled conditions only
Complete modality absence at inference. Partial degradation and intermittency are out of scope.
Embedding-level reconstruction only
Operates on learned representations. Does not extend to raw signal recovery or generation.
No temporal modelling
Single-instance prediction only. Streaming and event-driven failure modes are not addressed.
Empirical regularities, not formal guarantees
Fidelity established empirically. Error bounds and decision-theoretic guarantees remain open.
Federated proof-of-concept
Fixed client sets, IID partitions, FedAvg. Non-IID drift and client churn not addressed.
Looking Forward
There is always something more to do
Reconstructable representation design
Robustness ceiling is in the encoder, not the decoder. Cross-modal substitutability must be an explicit training objective.
Multimodal federated learning under incongruence
Non-IID drift, varying incongruency, client churn. Privacy and trustworthiness co-designed with reconstruction, not added post-hoc.
Trustworthiness
Reliability bounds on when reconstructed embeddings can be trusted.
Privacy & security
Reconstruction may recover sensitive attributes never explicitly shared.
Behavioural evaluation
Calibration, class-conditional fidelity as standard criteria. Not geometric similarity.
Multimodal learning is promised as the better approach, more context, more robustness. Making that promise real is hard work. This thesis, I hope, brings us one step closer to that ideal.
Thank You
Thank you
How Did We Get Here?
A Personal NoteOrigin & Reflections
The Brief
Emergency Response · Smart Cities · ITS
IoT sensor fusion, audio and video processing, real-time decision support. Applied and systems-level.
The ITS context anchors the federated chapter. The focus narrowed to the foundational problem: complete modality availability is assumed, rarely questioned, and often wrong.
How the questions formed
RQ1: What does missing look like?
Papers treated missing-modality results as a footnote. The gap was worth examining properly.
RQ2: Simple and post-hoc
Existing methods modified training. Small networks on frozen representations offered a cleaner separation and matching performance.
RQ3: Accuracy is not enough
Calibration and class-conditional behaviour told a different story than accuracy alone.
RQ4: The system as a whole
Federated settings with heterogeneous sensors were always the real context. Nobody had treated it as a unified problem.
What I learned along the way
Writing
Improving the writing improved the thinking. They turned out to be the same process.
Engineering
Code was never the problem. Framing and explaining the work was.
Questioning
Every significant result started with something that looked a bit off and was worth following.
Communication
Knowing when not to speak matters as much as knowing what to say.
Failure
Rejections came. Learning not to take them personally takes time.